java-tron核心模块¶
代码结构¶
java-tron是基于Java语言开发的TRON网络客户端,它实现了TRON白皮书中所提到的所有功能,包括共识机制、密码学、数据库、TVM虚拟机、网络管理等。我们可以通过启动java-tron来运行一个TRON网络节点。在本文中,我们将详细描述java-tron的代码结构,介绍其各个功能模块的作用,便于开发者后续的代码分析与开发。
java-tron采用模块化的代码结构,代码结构清晰,易于维护与扩展。java-tron 目前分为7个模块:protocol、common、chainbase、consensus、actuator、crypto、framework,下面分别介绍各个模块的功能及其代码组织结构。
protocol¶
对于区块链这种分布式网络,简洁高效的数据交互协议非常重要,protocol模块定义了:
- 节点间通信协议
- 节点内部模块间的通信协议
- 对外提供的服务协议
上述协议采用了Google Protobuf数据交互格式,相比于JSON和XML,Google Protobuf格式更高效和灵活,可以通过ProtoBuf编译器为定义的协议文件生成特定语言的序列化和反序列化的源代码。Protobuf是 java-tron 实现跨语言跨平台的基础。
protocol 模块的代码路径为https://github.com/tronprotocol/java-tron/tree/develop/protocol,其目录结构如下:
|-- protos
|-- api
| |-- api.proto
| |-- zksnark.proto
|-- core
|-- Discover.proto
|-- Tron.proto
|-- TronInventoryItems.proto
|-- contract
protos/api/- java-tron节点对外提供的gRPC接口及数据结构protos/core/- 节点间及节点内部各个模块间通信的数据结构Discover.proto- 节点发现相关的数据结构TronInventoryItems.proto- 节点间区块传输相关数据结构contract/- 合约相关的数据结构Tron.proto- 其它重要的数据结构定义,其中包括账户、区块、交易、资源、超级代表、投票、提案相关的数据结构。
common¶
common模块对公共组件和一些工具类进行了封装,比如异常处理、指标监控工具等,以方便其他模块调用。
common 模块的代码路径为https://github.com/tronprotocol/java-tron/tree/develop/common, 其目录结构如下:
|-- /common/src/main/java/org/tron
|-- common
| |-- args
| |-- config
| |-- entity
| |-- logsfilter
| |-- overlay
| |-- parameter
| |-- prometheus
| |-- runtime
| |-- setting
| |-- utils
|-- core
|-- config
|-- db
|-- db2
|-- exception
common/prometheus- prometheus指标监控common/utils- 基础数据类型封装类core/config- 节点配置相关类core/exception- 所有的TRON网络异常处理相关类
chainbase¶
chainbase 模块是数据库层面的抽象,像 PoW、PoS、DPoS 这类基于概率性的共识算法不可避免的会以一定的概率发生切链,因此 chainbase 定义了一个支持可回退数据库的接口标准,该接口要求数据库实现状态回滚机制、checkpoint容灾机制等。
另外 chainbase 模块具有良好的接口抽象设计,任何满足接口实现的数据库都可以作为区块链的底层存储,赋予开发者更多的灵活性,LevelDB和RocksDB是默认提供的两种具体实现。
chainbase 模块的代码路径为https://github.com/tronprotocol/java-tron/tree/develop/chainbase,其目录结构如下:
|-- chainbase.src.main.java.org.tron
|-- common
| |-- bloom
| |-- error
| |-- overlay
| |-- runtime
| |-- storage
| | |-- leveldb
| | |-- rocksdb
| |-- utils
| |-- zksnark
|-- core
|-- actuator
|-- capsule
|-- db
| |-- RevokingDatabase.java
| |-- TronStoreWithRevoking.java
| |-- ......
|-- db2
| |-- common
| |-- core
| |-- SnapshotManager.java
| |-- ......
|-- net
|-- service
|-- store
common/- 公共组件,比如异常处理类、工具类storage/leveldb/实现了使用LevelDB作为底层存储数据库storage/rocksdb/实现了使用RocksDB作为底层存储数据库
-
core/- chainbase模块核心代码-
capsule/各个数据结构的封装类,比如AccountCapsule,BlockCapsule等,AccountCapsule为Account数据结构的封装类,提供了账户数据的修改与查询;BlockCapsule为Block数据结构的封装类,提供了区块数据的修改与查询。
-
store/各个数据库,比如
AccountStore,ProposalStore等。AccountStore是账户数据库,数据库名称为account,存储了TRON网络中的所有账户信息;ProposalStore是提案数据库,数据库名称为proposal,存储了TRON网络中的所有提案信息。 -
db/和db2/实现了可回退数据库,其中包含了两种可回退数据库:位于
db/目录下AbstractRevokingStore和位于db2/目录下SnapshotManager。SnapshotManager相比与AbstractRevokingStore,数据回退更稳定,并支持底层数据库的扩展,因此java-tron采用SnapshotManager可回退数据库,其中的几个重要接口及实现类如下:RevokingDatabase.java是数据库容器的接口,用于所有可回退数据库的管理,SnapshotManager是该接口的一个实现TronStoreWithRevoking.java是支持可回退的数据库的基类,所有的可回退数据库都是它的具体实现,比如BlockStore,TransactionStore等
-
consensus¶
共识机制是区块链中非常重要的模块,常见的有 PoW、PoS、DPoS、PBFT 等,联盟链以及其他一些可信网络中也会采用 Paxos、Raft 等共识机制,共识的选择需要和业务场景相匹配,比如对共识效率敏感实时游戏类就不适合采用 PoW,而对实时性要求极高的交易所来说 PBFT 可能是首选。所以支持可替换的共识是非常有必要的,同时也是实现特定应用区块链的重要一环,consensus 模块最终目标是能够让应用开发者能够像配置参数那样简单的切换共识机制。
consensus 模块的代码路径为https://github.com/tronprotocol/java-tron/tree/develop/consensus,其目录结构如下:
|-- consensus/src/main/java/org/tron/consensus
|-- Consensus.java
|-- ConsensusDelegate.java
|-- base
| |-- ConsensusInterface.java
| |-- ......
|-- dpos
|-- pbft
start- 启动共识服务,可以自定制启动参数stop- 停止共识服务receiveBlock- 定义接收区块的共识逻辑validBlock- 定义验证区块的共识逻辑applyBlock- 定义处理区块的共识逻辑
目前java-tron基于 ConsensusInterface 接口实现了DPOS共识和PBFT共识,分别位于dpos/和pbft/目录下,开发者也可以根据自身业务需求实现 ConsensusInterface 接口,来自定义共识机制。
actuator¶
以太坊初创性的引入了虚拟机并定义了智能合约这种开发方式,但对于一些复杂的应用,智能合约不够灵活且受限于性能,这也是 java-tron 提供创建应用链的一个原因。为此 java-tron 独立出来了 actuator 模块,该模块为应用开发者提供一种新的开发范式:可以将应用代码直接植入链中而不再将应用代码跑在虚拟机中。
actuator是交易的执行器,可以将应用看成是不同交易类型组成的交易集,每类交易都由对应的 actuator 负责执行。
actuator 模块的代码路径为https://github.com/tronprotocol/java-tron/tree/develop/actuator,其目录结构如下:
|-- actuator/src/main/java/org/tron/core
|-- actuator
| |-- AbstractActuator.java
| |-- ActuatorCreator.java
| |-- ActuatorFactory.java
| |-- TransferActuator.java
| |-- VMActuator.java
| |-- ......
|-- utils
|-- vm
actuator/- TRON网络中各种类型交易的执行器,定义了不同类型交易的处理逻辑,比如TransferActuator是转账TRX交易的处理类,FreezeBalanceV2Actuator是质押TRX获取资源交易的处理类utils/- 执行交易所需的工具类vm/- 虚拟机相关代码
actuator模块定义的 Actuator 接口有4个方法:
* execute - 负责交易具体需要执行的动作,可以是状态修改、流程跳转、逻辑判断
* validate - 负责验证交易的正确性
* getOwnerAddress - 获取交易发起方的地址
* calcFee - 定义交易手续费计算逻辑
开发者也可以根据自身业务实现 Actuator 接口,来实现自定义交易类型的处理。
crypto¶
crypto是一个相对独立的模块,但也是非常重要的模块,java-tron中的数据安全几乎全由该模块来保证,目前支持SM2和ECKey加密算法。
crypto模块的路径为https://github.com/tronprotocol/java-tron/tree/develop/crypto,其目录结构如下:
|-- crypto/src/main/java/org/tron/common/crypto
|-- Blake2bfMessageDigest.java
|-- ECKey.java
|-- Hash.java
|-- SignInterface.java
|-- SignUtils.java
|-- SignatureInterface.java
|-- cryptohash
|-- jce
|-- sm2
|-- zksnark
sm2和jce- 提供SM2和ECKey加密算法和签名算法zksnark- 提供零知识证明算法
framework¶
framework是 java-tron 的核心模块,也是节点的入口,framework 模块负责各个模块的初始化及业务逻辑的跳转,framework包含了节点对外提供的服务,P2P网络相关的节点发现与管理流程、区块广播及处理流程。
framework模块的代码路径为https://github.com/tronprotocol/java-tron/tree/develop/framework,其目录结构如下:
|-- framework/src/main/java/org/tron
|-- common
| |-- application
| |-- backup
| |-- logsfilter
| |-- net
| |-- overlay
| | |-- client
| | |-- discover
| | |-- message
| | |-- server
| |-- runtime
| |-- zksnark
|-- core
| |-- Wallet.java
| |-- capsule
| |-- config
| |-- consensus
| |-- db
| |-- metrics
| |-- net
| |-- services
| |-- trie
| |-- zen
|-- keystore
|-- program
| |-- FullNode.java
|-- tool
program/FullNode.java- 它是程序的入口点,初始化对外的HTTP、gRPC和json-rpc接口服务core/services- 定义了对外提供的服务,其子目录http/包含了所有的http接口处理类,json-rpc/包含了所有的json-rpc接口处理类common/overlay/discover- 节点发现逻辑common/overlay/server- 节点管理及节点间区块同步逻辑core/net- 消息处理,其子目录/service为交易及区块广播、区块抓取及同步逻辑core/db/Manager.java- 交易及区块校验并处理逻辑
总结¶
本文主要介绍了java-tron的代码结构,以及各个功能模块的作用、位置及目录结构,通过本文您会对java-tron的整体结构及关键接口有了大致的了解,方便后续的代码分析和开发。
ChainBase¶
概览¶
众所周知区块链本质上是一个不可篡改的分布式账本,非常适合解决信任的问题,现实中往往利用区块链来进行记账和交易,比如很多应用采用 BTC、ETH、TRX 等数字货币来进行经济活动以保证资金的公开透明。
而实现这样一个不可篡改的分布式账本是一个非常复杂的系统工程,涉及到很多技术领域:比如 p2p 网络、智能合约、数据库、密码学、共识机制等。其中数据库作为底层存储的基础,各个区块链团队都在探索数据库层面的设计与优化。
java-tron 的数据库模块也称为ChainBase 模块,本文主要介绍一些背景知识,并通过介绍交易处理、状态回滚、数据持久化等逻辑为开发者展现ChainBase 模块的实现细节。
预备知识¶
数据库是区块链系统中重要的一环,它存储了区块链上的所有数据,是区块链系统正常运行的基础,每个全节点都保存了一份全量的数据,包含区块数据和状态数据,java-tron 采用 Account 模型来保存用户的账户状态。
账户模型¶
目前主流的账户模型有两种:
- UTXO模型
- Account模型
UTXO 模型是无状态的,能更容易并发处理交易,并且拥有较好的隐私性,但在编程灵活度方面有所欠缺。
Account 模型中用户数据都存放在对应的账户中,并且智能合约也以代码的形式存放在 Account中,这种模型更加直观,开发人员更容易理解。出于可编程性,灵活性等方面的考虑,java-tron 采用了 Account 模型。
共识¶
目前主流的共识有 PoW、PoS、DPoS 等。PoW 即工作量证明,所有节点都参与计算一个预期的 hash 结果,优先计算出结果的节点拥有出块的权利,但是随着算力不断增长,计算 hash 所需的能耗也在不断增大,而且大矿场垄断了大部分的算力,这也违背了去中心化的初衷。
为了解决 PoW 所面临的问题,有人提出了PoS(Proof of Stake),简单理解为:持币越多的节点获得出块权利的概率就越大,但这样会导致垄断问题,所以又对 PoS 进行了改进,提出了 DPoS(Delegated Proof of Stake):通过选举出的超级代表来保证去中心化特性,同时超级代表轮流负责出块来提高了出块的效率。java-tron 目前采用 DPoS 共识机制。
更多细节可参看:Delegated Proof of Stake
持久化存储¶
区块链业务和传统互联网业务存在一定的区别,区块链业务在数据库层面并没有特别复杂的处理逻辑,但区块链中存在大量key-value的读写操作,所以对数据的读写性能有着较高的要求。
基于这方面的考虑,java-tron 默认采用 LevelDB 作为底层数据存储,并且 java-tron 有着良好的架构设计,采用面向接口编程的模式使得 chainbase 模块拥有着较好的扩展性,任何实现了 chainbase 接口的数据库都可以作为 java-tron 的底层存储引擎,比如在 chainbase v2 版本中提供了基于 RocksDB 的数据库实现。
交易验证¶
众所周知区块链中主要存储的是交易数据,介绍 chainbase 模块前需要首先了解 java-tron 中交易的处理逻辑。
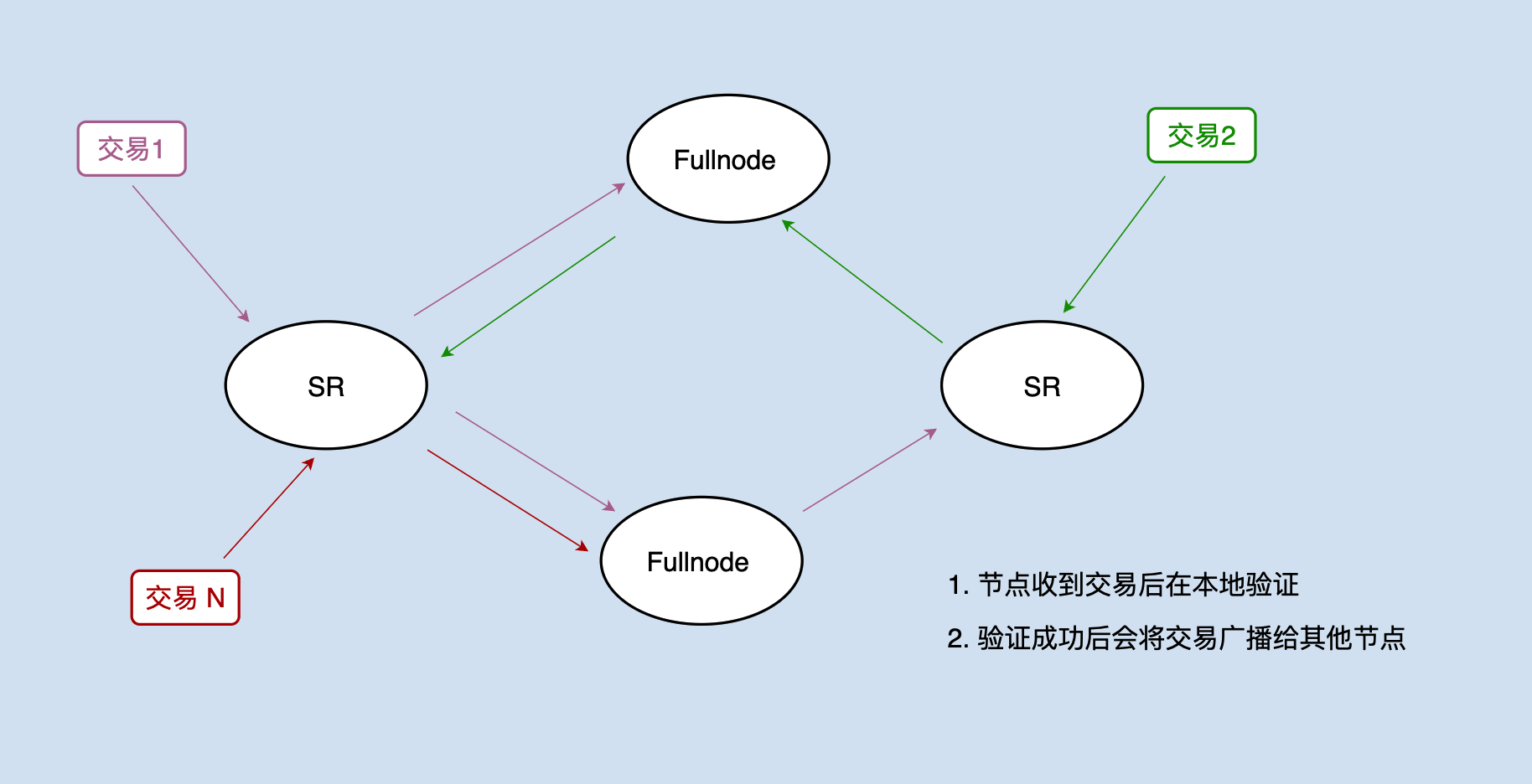
交易会通过网络广播分发到各个节点,节点接收交易后,首先会对交易的签名做校验,验证成功后还需要对交易进行预执行,以此来判断该交易是否合法。
注:java-tron 的具体实现和上图有所偏差,同时为了方便起见,本文将 FullNode 节点和 SR 统称为节点。
比如处理一笔转账交易:用户A向用户B转账100个 TRX,需要验证用户A是否有足够的余额来进行转账。
数据库中的 account 库保存了所有用户的账户信息,包括用户的余额信息,那如何判断这个转账交易是否合法?java-tron 的逻辑是:当从网络中接收到交易后,会立即执行该交易操作,即在本地的数据库中将账户信息进行修改:(accountA - 100TRX,accountB + 100TRX)。假如这个操作能够执行成功,那么说明至少在当前状态下这个交易是合法的,可以打包至区块中。
名词解释¶
SR:超级代表(Super Representative),负责产块
FullNode:全节点,存储全量区块数据,负责交易、区块的广播和校验,并提供查询服务
TRX:波场原生代币
状态回滚¶
上面我们讲到java-tron通过预执行来验证交易是否合法,但我们需要知道的是该交易在某个节点上验证成功并不代表该交易已成功上链,因为该交易并未打包到已共识的区块中,存在被回滚的风险。
java-tron 的共识遵循了一个原则:即超过2/3个超级代表认同的区块中的交易才是真正成功上链的交易。也可以理解为:
- 交易被打包进入区块
- 该区块被超过2/3个 SR 所接受
满足上述两点的交易才是成功上链的交易。java-tron 中一个交易被最终确认需要经历三个阶段:
- 交易校验
- 交易打包进区块
- 该区块被网络大部分节点接收并应用
这也就引出了一个问题:在 java-tron 的实现中,一个节点如果对交易做验证后,它的数据库状态随之进行了改变,假如这个交易最终并未打包进区块或该区块并未满足超过2/3个 SR 接受,那这个节点的状态和整个网络的状态就会不一致。
所以除了处理被超过2/3个SR认可的区块中的交易数据外,其余所有对交易做处理而产生的数据状态的变化都有可能需要回滚。而且需要回滚的情况不止一种,总共三种:
- 接收到新的区块后,回滚交易验证产生的状态变更
- 生产区块后,回滚交易验证产生的状态变更
- 若发现分叉链,回滚分叉链中区块的交易产生的状态变更
这3种情况造成的数据状态变化都有可能需要回滚。下面依次讲解为何这三处需要回滚。
接收新区块后的状态回滚¶
在接收到新的区块时,节点需要回滚到上个区块的结束时状态,回滚掉所有之后验证的交易。如下图所示:
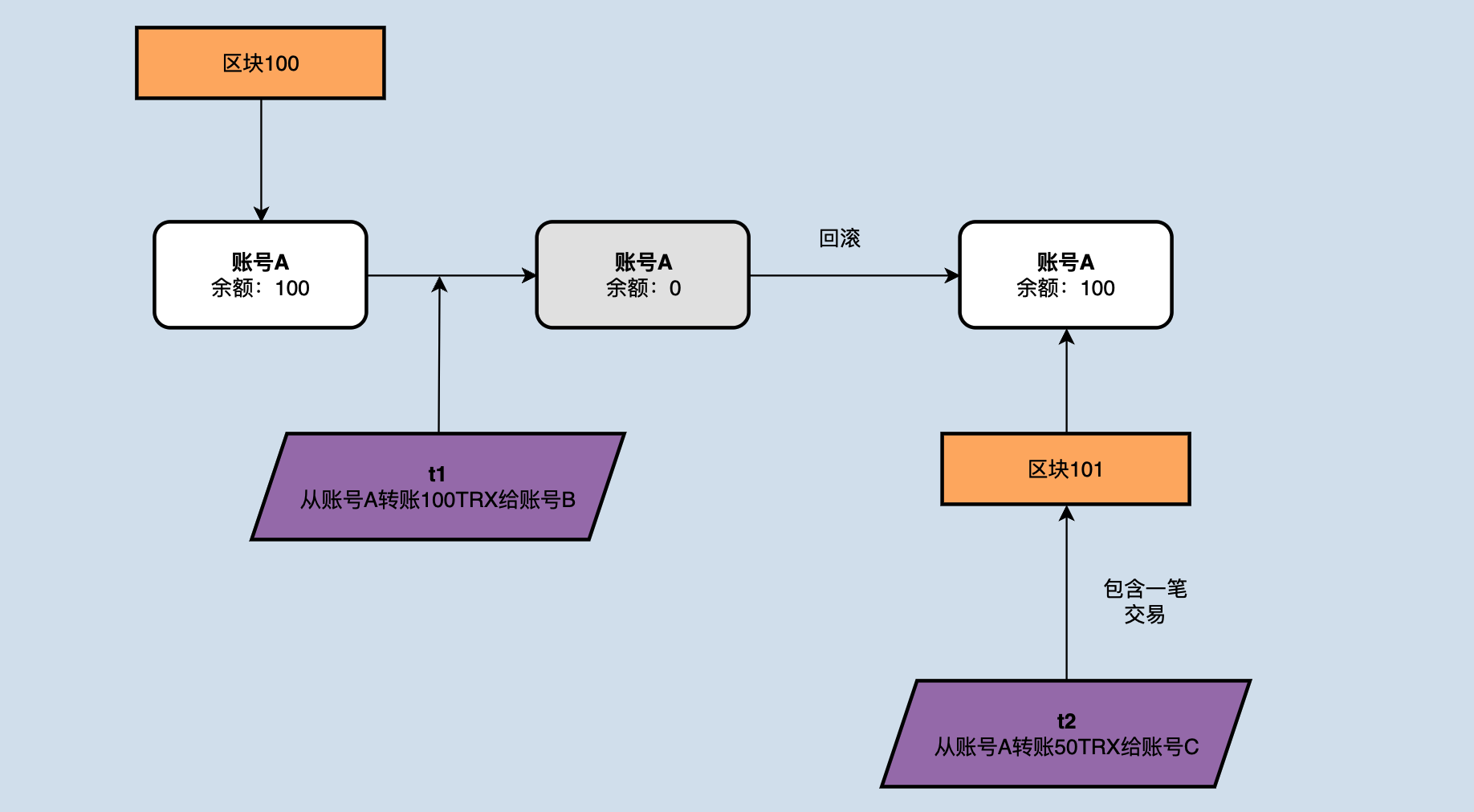
假如节点在区块高度为1000时 accountA 账户余额为100,此时接收并校验了一个转账交易t1,并将自己的100TRX转账给了 accountB,当接收到了新的block1001后,该block包含了一个 accountA 转50TRX给 accountC 的交易t2,理论上t2已经打包进区块,优先级是要优于t1,但是如果不做任何操作的话,t2的校验将无法通过,因为 accountA 没有足够的余额,所以在接收到新的区块1001后,需要将交易t1所产生的的状态变更进行回滚。
生产区块后的状态回滚¶
首先读者可能会有一个疑问:已经验证过的交易直接打包到区块中即可,也不会对数据库状态造成改变,为何还有数据库状态的变更?
因为java-tron 在将交易打包到区块时对交易做了二次校验,做二次校验是因为交易的时效性问题,依然以上图为例,图中可以得知在接收到区块1001后对交易t1进行了回滚,并且将 accountA 的余额减去50,之后轮到该节点打包出块,但是此时t1已经变成一个非法的交易,因为 accountA 中的余额已经不够支付100个TRX,直接将t1打包进区块必然不可取,所以需要对交易再次进行校验,这也就是在区块打包时依然需要对交易做二次校验的原因。
而区块打包成功后,该节点会将向网络广播该区块,同时也在本地 apply该区块,而 apply 的逻辑则会对区块中的交易再次校验,所以在打包完区块后仍然需要执行回滚操作。
分叉链的状态回滚¶
这是最后一种回滚的情况,区块链不可避免的会出现分叉的情况,尤其是基于 DPoS 这种出块速度较快的区块链系统更容易出现分叉的情况。
java-tron 在内存维护了一个如图所示的数据结构:
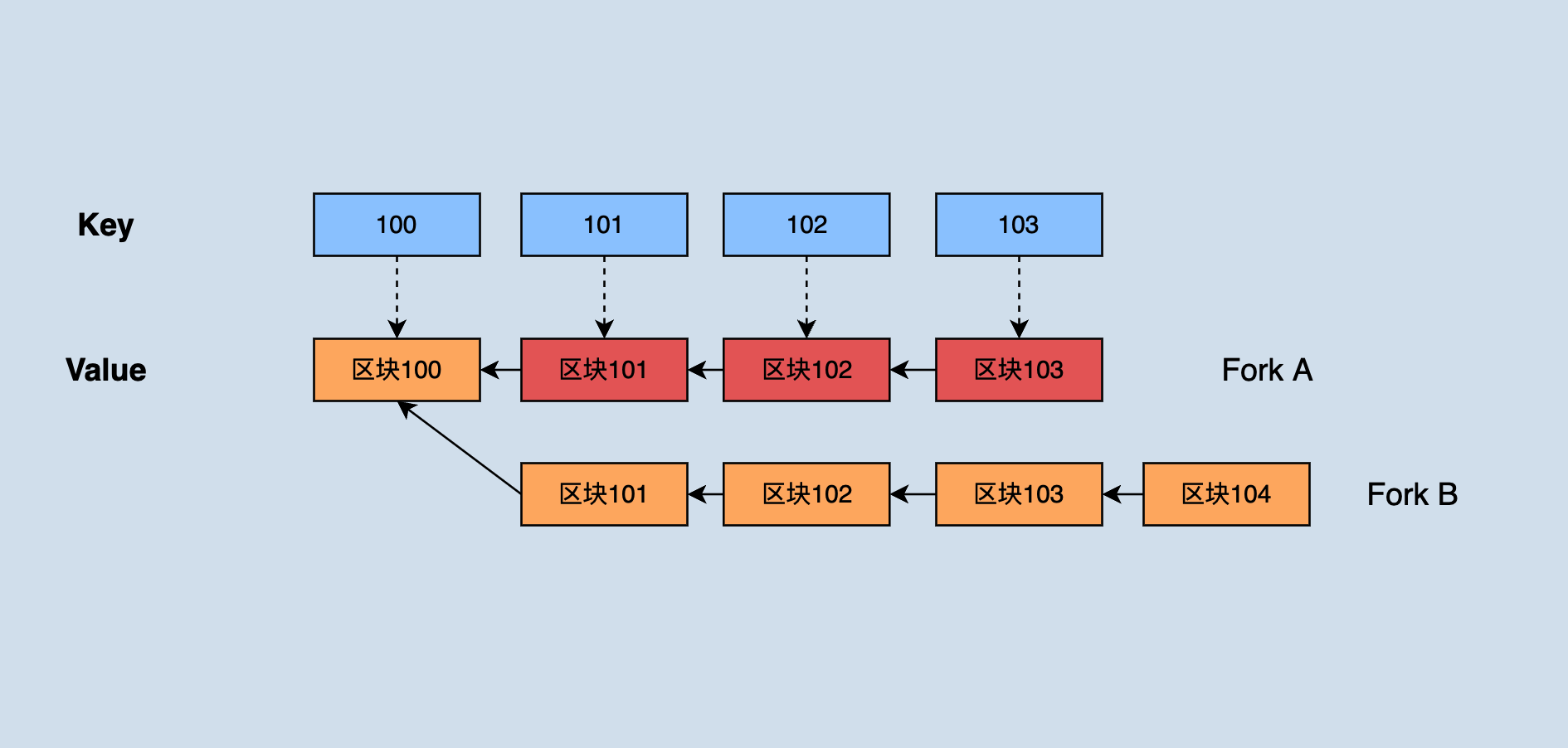
java-tron保存了最近还未达成共识的所有区块。当出现分叉链时,根据最长链原则:假如分叉链的区块高度大于目前主链区块高度,则需要将分叉链切换成主链,切换时就需要回滚掉之前主链上的一部分区块直到它们共同的父区块,然后从该父区块处依次 apply 新的主链区块。
如图,深色部分的 fork A 原先为主链,由于fork B 的高度不断增长最终超过了 A 的高度,此时就需要回滚掉 fork A 中高度为1003、1002、1001的三个区块数据,然后依次 apply fork B 中 1001'、1002'、1003'、1004'区块。
状态回滚实现¶
本章节从代码的角度讲解接收交易、交易验证、生成区块、验证区块、保存区块,来更进一步解析java-tron的chainbase模块。如没有特殊声明,则默认描述的为Fullnode(包含SR)的逻辑。
交易接收¶
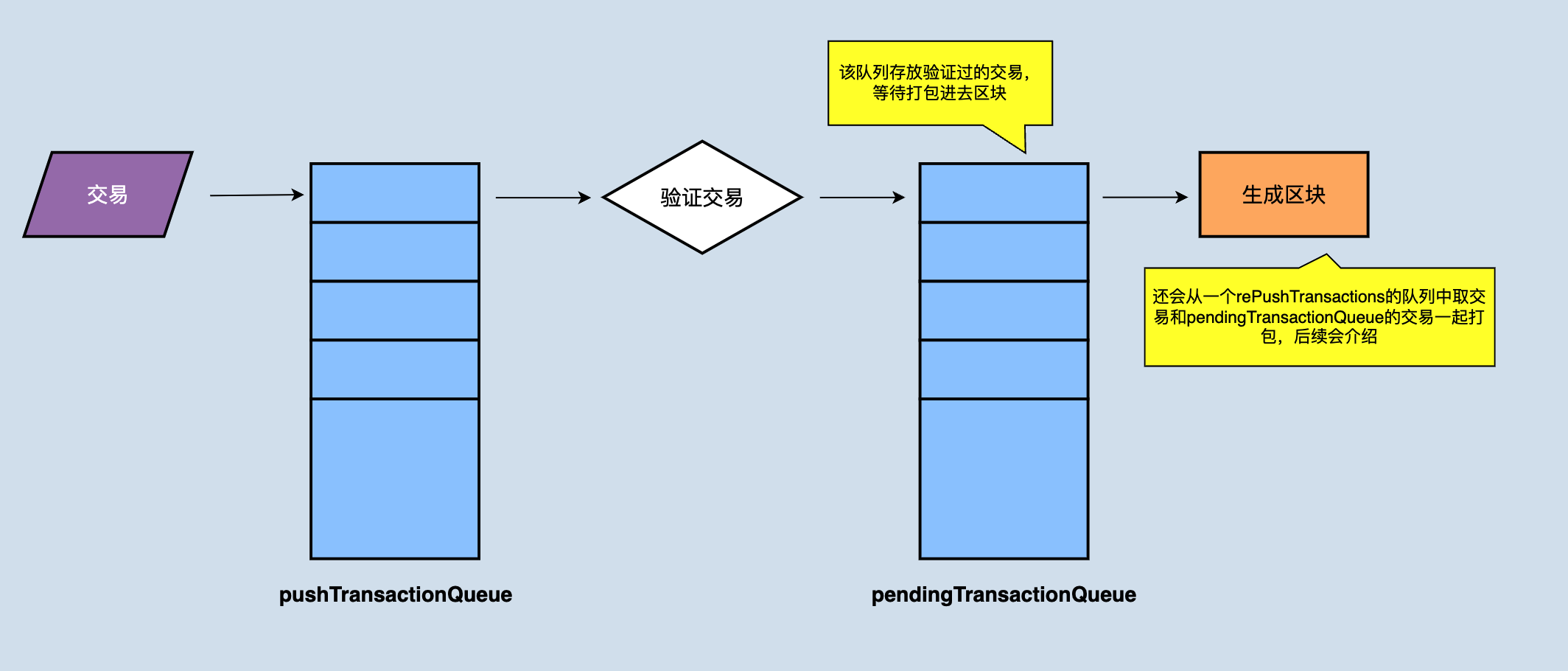
节点收到广播过来的交易后,通过调用Manager类的pushTransaction(final TransactionCapsule trx)函数将交易放到本地的pushTransactionQueue缓存队列,同时对该交易进行验证,此方法的返回比较考究:
- 如果验证成功直接返回true
- 对于用户通过API向节点发送的交易,交易验证失败,会抛出异常,用户会拿到异常信息。对于节点通过P2P网络从其他节点接受到的交易只会将异常记录在本地。
交易验证成功之后,没有问题的交易会放入pendingTransactionQueue,pendingTransactionQueue负责在生成区块时提供交易集合。如果节点为SR节点时,当轮到到它产块时,就从pendingTransactionQueue中拿出来全部或者部分(取决于pendingTransactionQueue中有多少交易)来生成一个区块。
收到新区块时的状态回滚¶
节点在收到新区块前也会收到交易广播或收到来自其他节点的交易广播,需要对接收到的交易进行验证来判断该交易是否能正确的执行,验证也就意味着需要改变状态,而验证成功的交易并不代表这个交易就一定能最终执行,还要再经过打包进区块和固化的过程,这步可以认为是提前先筛选掉那些明显错误的交易,这里只是验证。 所以新的区块到来时这些交易验证所产生的状态都是应该被回滚掉的,只有在apply 区块时产生的状态变更才不会回滚。
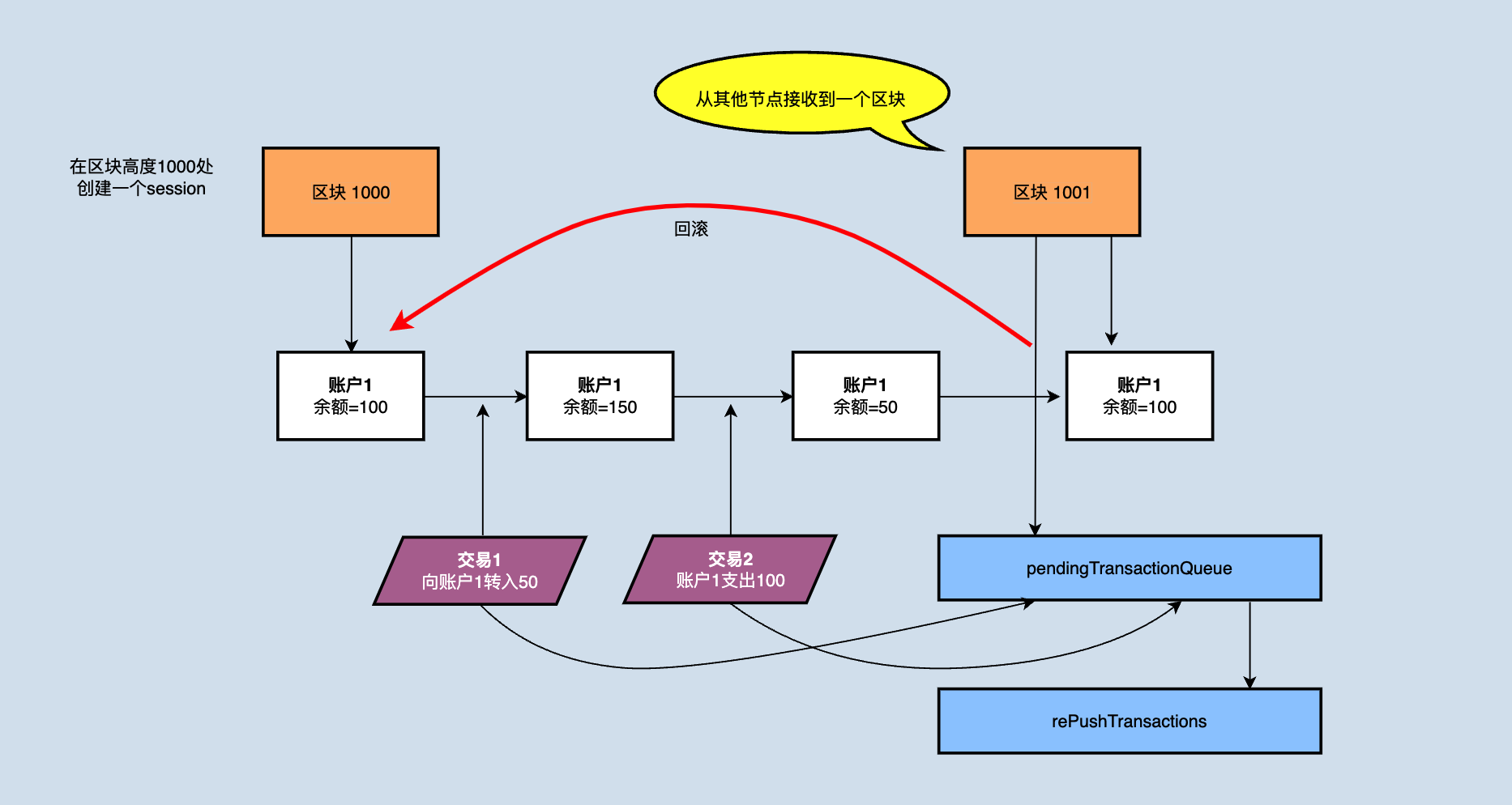
回滚时需要将pendingTransactionQueue中的交易挪至rePushTransactions,并清空pendingTransactionQueue,详细解释看图。
为什么新的区块到来后需要清空pendingTransactionQueue?首先明确一点,pendingTransactionQueue队列负责在生成区块时提供交易数据,也就是说存放的是验证过的可以直接打包进区块的交易,但是因为新的区块也会对账户状态进行变更,可能pendingTransactionQueue里面之前验证没问题的交易在apply新的区块后验证不通过(最简单的例子:新区块某笔交易是账户A花费了一部分token,导致账户A在队列中的某笔交易金额不够支付了)。将交易挪至rePushTransactions后会有后台线程专门负责对该队列中的交易再次验证,如果没有问题就再次放进pendingTransactionQueue,为产生区块提供数据。
java-tron中存在一个session对象,一个session表示的是一个区块对状态的变更,session对象主要用来回滚,比如将状态回滚到上一个区块的状态都需要通过session来操作,如下图所示:
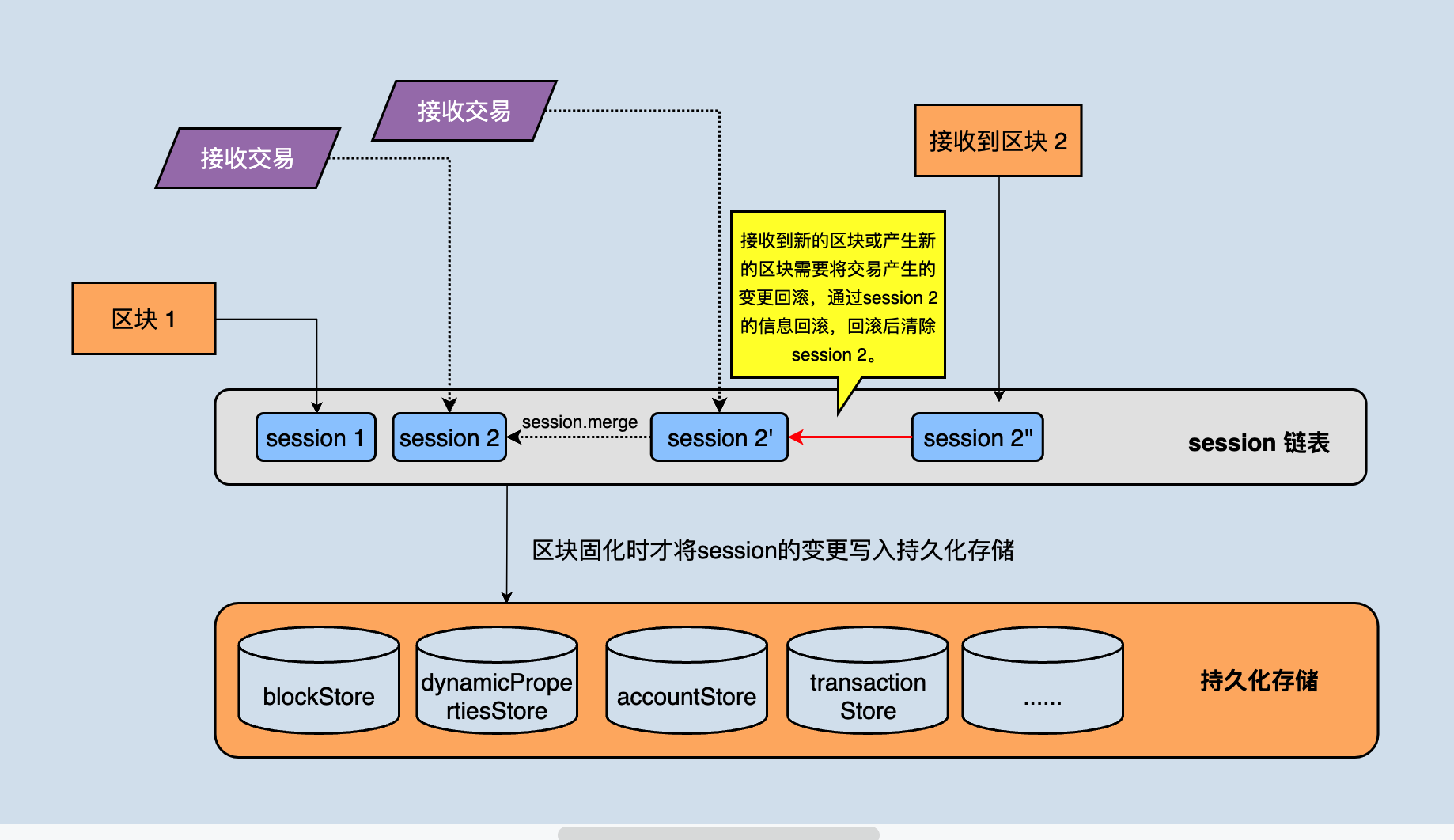
上图图中能看到持久化存储中有很多不同类型的数据库,就是这些数据共同组织成一个完整的区块链,比如区块存储在 khasodb 和 blockStore 中,账户信息存储在 accountStore 中....
节点维护了一个 session 链表,该链表存储的是区块/交易对应的变更信息,节点可以通过这些变更信息进行回退。上图中 session1 是当前最高区块的对状态的变更,当次接收到一个交易后会产生一个新的 session2 ,后续接收一个交易都会产生一个临时的tmpSession,该交易验证后,tmpSession立马合并到session2中,再次接受到一个新区块之前,所有的交易验证产生的状态变更都会保存在 session2 中,当有新区块到来时,直接执行 session2 的 reset 方法即可将状态回滚到上个区块。
生产区块时的状态回滚¶
SR生产区块前需要回滚,原因比较复杂,我们先考虑一个场景:
- pendingTransactionQueue 中存放是当前已经验证过的交易,所以某SR节点产块时只要直接打包pendingTransactionQueue 中的交易进区块,打包完之后将状态回滚到上一个区块的状态即可。
但是这种方案存在一个问题:假如该 SR 节点刚刚接收并 apply 一个新的区块,从前面的内容可知 pendingTransactionQueue 将被清空至rePushTransactions,此时正好轮到这个 SR 打包区块了,但 SR 的 pendingTransactionQueue 中没有什么交易。所以真正的实现是,产块时不止从 pendingTransactionQueue 读取交易,如果 pendingTransactionQueue 中交易较少时,还会从 rePushTransactions 中读取交易来放进区块,而通过上面的分析可知 rePushTransactions 中的交易有可能已经不能通过了,所以需要对交易再次进行验证。而正是因为有这个验证逻辑,才需要在出块前先将状态回滚。
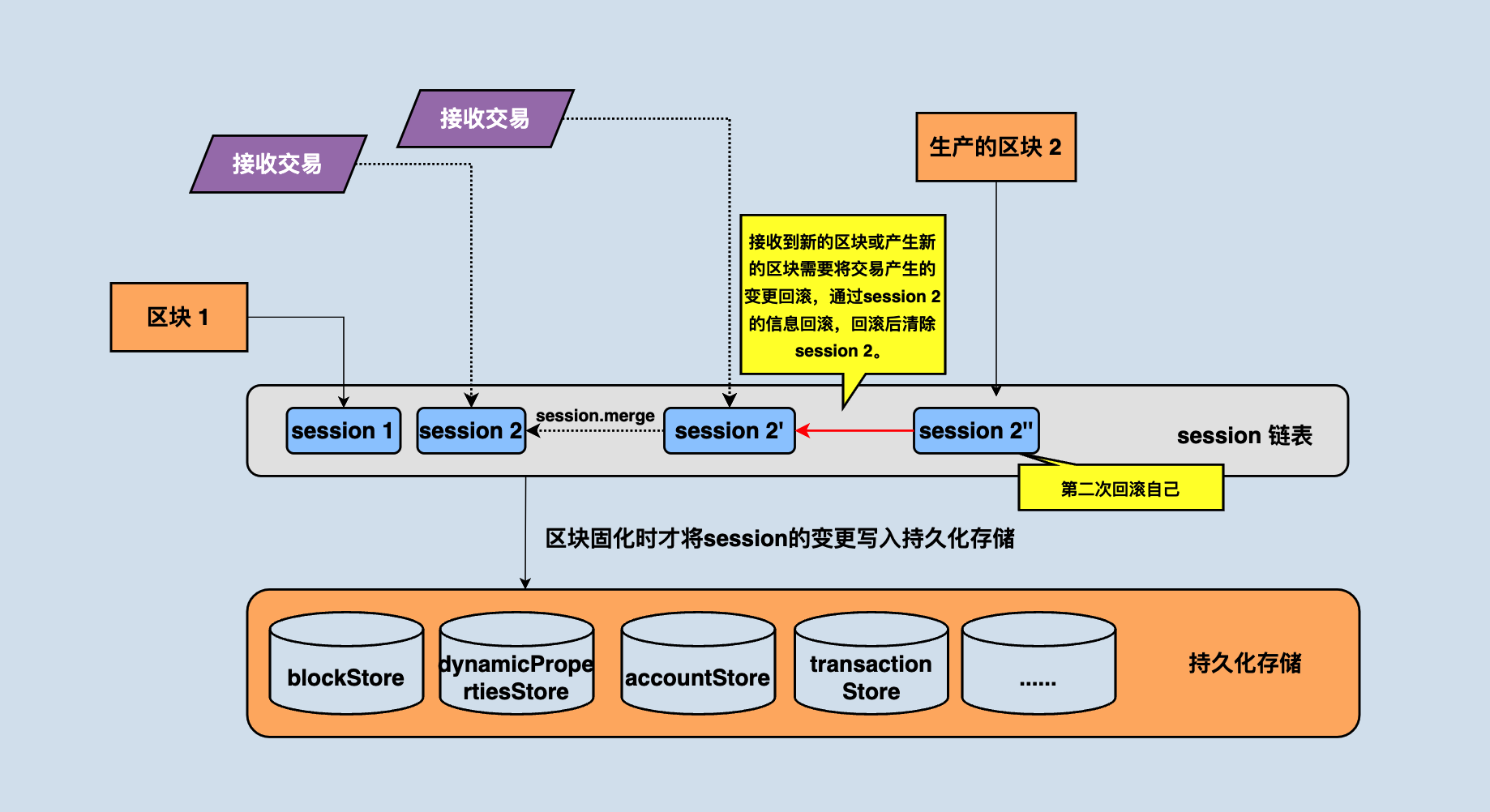
生产区块的过程中会对交易再次验证,所以会产生状态变更,但这是只是区块生成, 还需要广播区块,由广播接受到的区块会真正的改变状态,所以生成区块所产生的状态变更也需要被回滚掉。如上图所示,当区块生产完成后, 还需要将session2'' 回滚掉。
区块持久化¶
java-tron采用的是 DPOS 共识机制, java-tron 的 DPOS 是投票选出来27个节点当出块节点(也称为SR),SR有出块的权利和义务,并且被超过2/3个SR认可的block即为已经达成一致意见的区块,这些区块不能再被回滚,也称为固化块,只有固化的区块才能被写入数据库,
java-tron中 SnapshotManager 是存储模块的关键入口,持有了当前所有业务数据库的引用,并将数据库引用存储在一个列表中。每个数据库实例都支持在自身的基础上新增一层状态集:SnapshotImpl,SnapshotImpl 是一个内存 HashMap,多个 SnapshotImpl 通过链表形式关联,一个 SnapshotImpl 保留一次状态变更所涉及的数据修改,且 SnapshotImpl 之间相互独立,通过这种数据结构来将每个状态独立开,如下图所示:
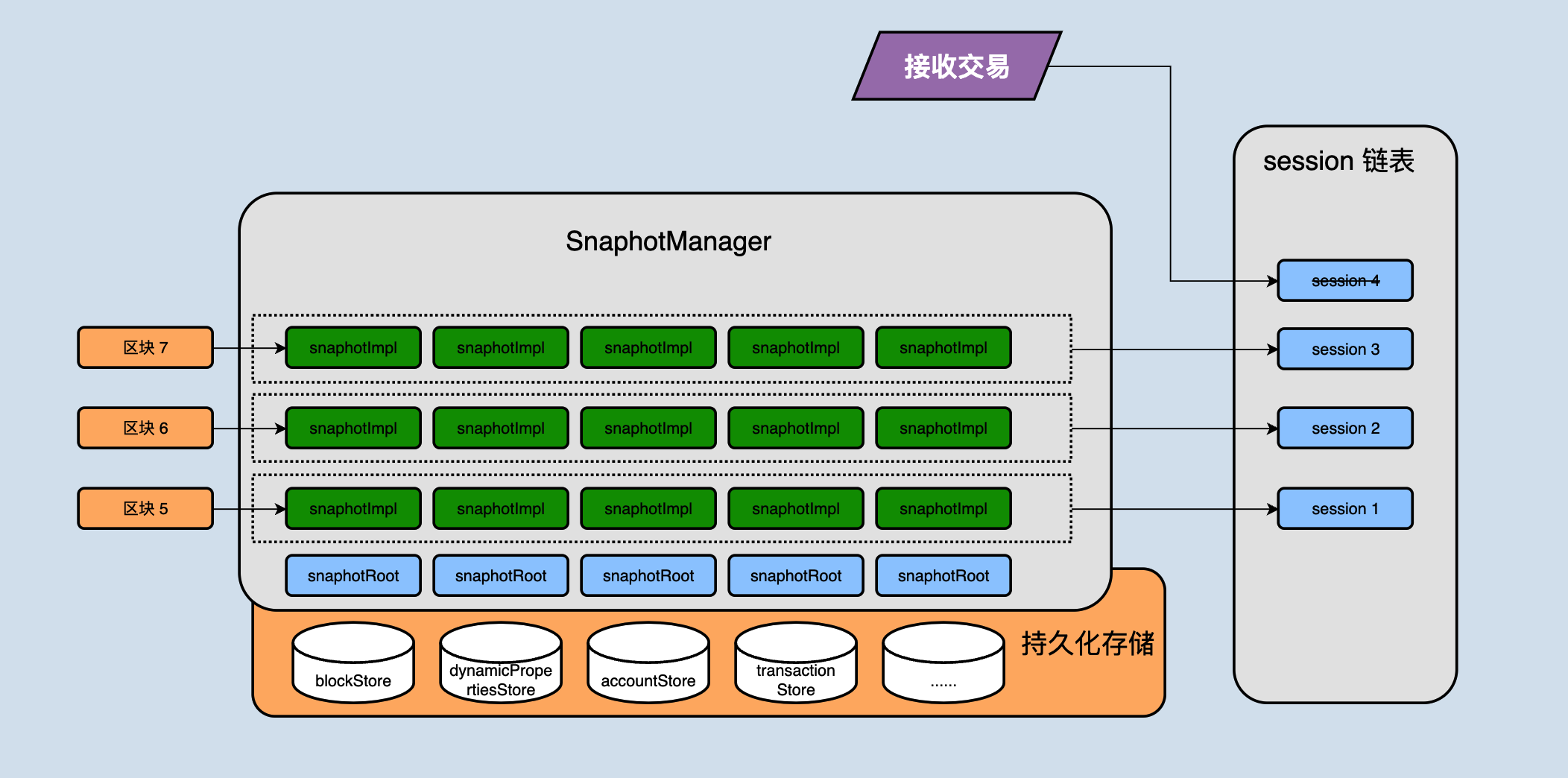
上图中 SnapshotRoot 是对持久化数据库的封装类,负责存储已固化的数据。
前面的章节中我们讲到session,一个session表示的是一个区块对状态的变更,实际上一个session包含了各个数据库对应SnapshotImpl,比如上图中区块5这一层所有的 SnapshotImpl 共同构成了区块5对整个数据库的变更。
节点接收到新区块后产生的变更不会直接存储到持久化存储中,而是首先存在 snapshotImpl 中,每接收一个区块对应产生一个snapshotImpl 不断的接收区块会导致 snapshotImpl 越来越多,什么时候会写入到持久化存储中呢?
SnapshotManager 中存在两个变量:size 和 maxSize,size 此处我们简单理解为目前内存中有多少层 snapshotImpl,maxSIze 则表示目前固化块和最新块高度的差值。
这样就很明显了,如果 size > maxSize,那么说明最开始的 size-maxSize 层的snapshotImpl 对应的区块已经是固化块了,它们可以落盘了,然后会将应该落盘的 snapshotImpl 合并到持久化存储中,这样来确保 snapshotImpl 不会占用过多的内存,而且也保证了固化块能够被及时的持久化存储下来。
数据库原子性¶
java-tron 的数据库存储与其他公链略有区别,例如以太坊持久化层只采用了一个数据库实例,以太坊中的不同类型的数据用前缀加以区分,存储在一个数据库实例中。而 java-tron 目前则将不同业务类型的数据存放在各自的数据库实例中。
两者实现方式各有千秋,单实例方便维护,能够统一写入,但缺点也较明显,比如随着时间推移单库数据量不断增长,某些业务数据库的频繁访问可能会拖累其他业务的读写性能。
多实例则不存在各个业务数据读写相互影响的问题,且可以根据各自的数据量与性能要求配置不同的参数,达到性能最大化,还可以将数据量较大的库独立拆分出去,以缓解数据膨胀问题。但多数据库实例存在一个严重的问题:并没有原生工具支持多数据库实例之间的原子写入。
java-tron 为了保证数据库多实例的原子写入,新增了 checkpoint 机制,在多实例落盘前将变更的数据统一写入 checkpoint,若多个数据库实例在写入时发生意外,服务重启时从 checkpoint 中将变更的数据统一恢复,保证写入的原子性。
上一节中固化块的 snapshotImpl 写入数据库的过程主要包含了两步:
- 创建 checkpoint
- snapshotImpl 执行落盘操作
创建 checkpoint 这个操作比较关键, checkpoint 是将内存中需要写入数据库的 snapshotImpl 先持久化的存储在一个 tmp 的数据库中(目前底层实现的是leveldb、rocksdb),创建 checkpoint 成功之后才会进行 snapshotimpl 的落盘操作,假如此时落盘时机器宕机,那么节点再次启动时,会首先搜索是否存在 tmp 的 checkpoint 数据,如果存在的话,会将 checkpoint 中的数据回放至 snapshotRoot 中。
Checkpoint 数据结构如下:
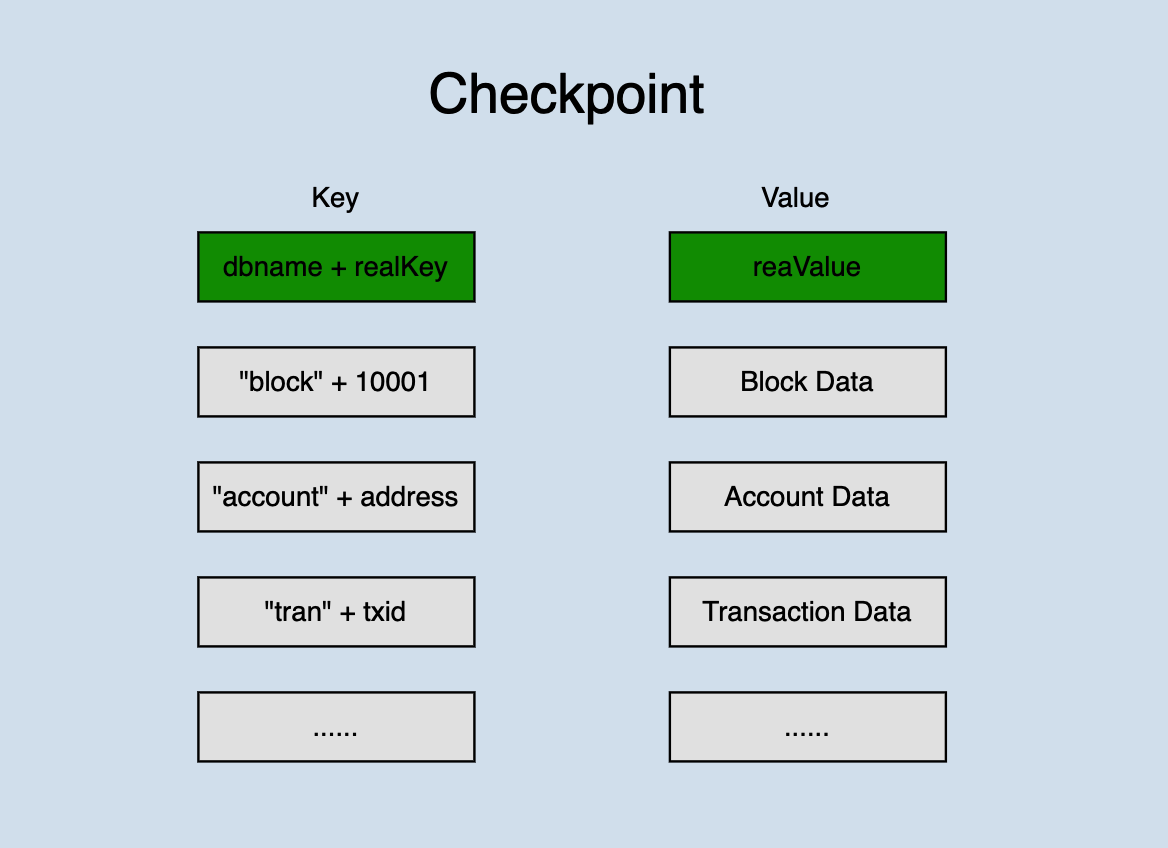
checkpoint将一次状态变更的所有数据统一存放在一个数据库中,不同类型的数据采用前缀加以区分,并且为了保证本次所有的变更数据能够全部落盘,写入时采用数据库底层调用writeBatch() 的方式。
这种解决的思路可以总结为:
- 多数据库实例之间无法保证写入的原子性,但单数据库(大部分主流数据库)支持原子性写入
- 将需要保证原子性写入的数据集首先采用原子写入的方式,写入到一个临时库,然后将数据分别写入不同的数据库实例,如果发生意外,通过临时库的数据来恢复即可。
总结¶
本文通过交易和区块的处理流程来分析了 chainbase 模块中回滚和数据库写入的实现细节,还分析了数据库多实例的原子写入的原理,防止意外宕机导致数据库损坏,希望通过阅读本文能有助于开发者进一步了解和开发java-tron数据库。
网络¶
概述¶
P2P是一种分布式网络,网络的参与者共享他们所拥有的一部分硬件资源,比如处理能力、存储能力、网络连接能力、打印机等,这些共享的资源需要由网络提供服务和内容,能被其它对等节点直接访问而无需经过中间实体。在此网络中的参与者既是服务和内容提供者,又是服务和内容获取者。
区别于传统的Client/Server中央服务器结构,P2P网络中的每个节点的地位都是对等的。每个节点在充当客户端的同时,也可以作为服务端给其它节点提供服务,极大地提高了资源的利用率。
区块链网络¶
P2P 是区块链结构中的网络层,网络层的主要目的是实现区块链网络中节点之间的信息传播、验证和交流。区块链网络本质上是一个P2P网络,每个节点既能接受信息也能产生信息。节点之间通过维护一个共同的区块链数据来保持通信。
P2P网络作为区块链的基础,为区块链带来如下优点:
- 防止单点攻击
- 高容错性
- 较好的兼容性与可扩展性
TRON网络¶
TRON架构图如下:
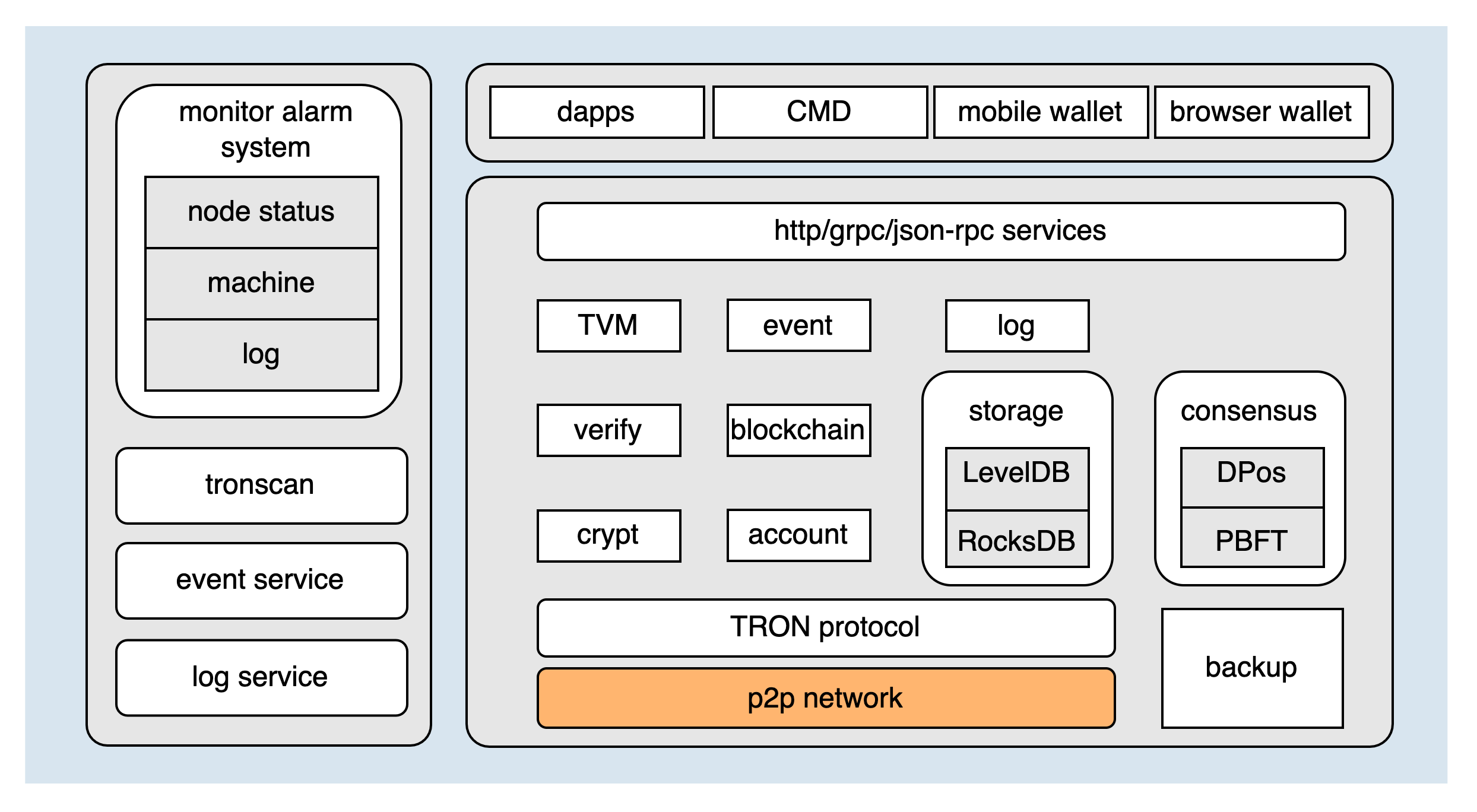
P2P网络作为TRON的最底层模块,直接决定了整个区块链网络的稳定性。网络模块按照功能可以划分成以下四部分:
下面将分别介绍这四个功能部分。
节点发现¶
节点发现是区块链节点接入区块链网络的第一步。区块链网络是一种结构化的P2P网络。结构化网络会将所有节点按照某种结构有序的组织起来,比如形成一个环状网络或者树状的网络。 结构化网络普遍基于DHT(Distributed Hash Table,分布式哈希表) 算法实现。具体的实现方案有 Chord、Pastry、CAN、Kademlia 等算法。TRON 网络采用 Kademlia 算法。
Kademlia 算法¶
Kademlia 是分布式散列表(DHT,Distributed Hash Table)的一种实现,是去中心化 P2P 网络中最核心的一种路由寻址技术,可以在无中心服务器的情况下,在网络中快速找到目标节点。
关于算法的详细介绍请参考 Kademlia。
TRON 实现¶
TRON 实现的 Kademlia 算法,要点如下:
- 节点ID:随机产生的512bit ID
- 节点距离:节点距离通过两个节点的ID异或运算得到,公式为:
节点距离 = 256 - 节点ID异或结果的前导0的个数,如果计算结果为负数,距离等于0。 - k桶:即节点路由表。根据节点距离的远近,将远端节点划分到不同的桶中,与本节点距离相同的远端节点被记录在相同的桶中,每个桶最多容纳16个节点。根据节点距离的计算公式就可以看出,TRON 实现的 Kademlia 算法一共维护256个桶。
TRON 节点发现协议包括以下四种UDP消息:
DISCOVER_PING- 用于探测⼀个节点是否在线DISCOVER_PONG- 用于响应DISCOVER_PING消息DISCOVER_FIND_NODE- 用于查找与⽬标节点距离最近的其它节点DISCOVER_NEIGHBORS- 用于响应DISCOVER_FIND_NODE消息,会返回一个或者多个节点,最多16个
初始化K桶¶
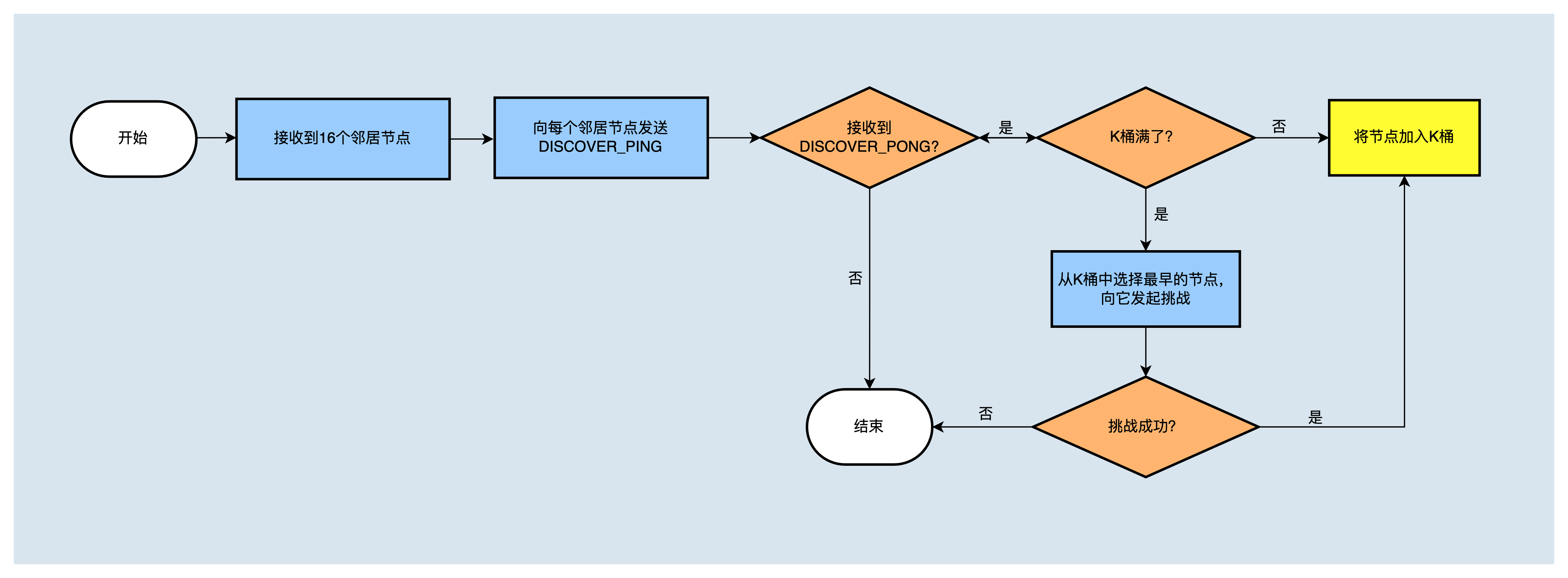
节点启动后,会读取节点配置文件中配置的种子节点,以及数据库中记录的对等节点,然后向它们发送 DISCOVER_PING 消息,如果收到回复 DISCOVER_PONG ,在K桶没满的情况下,将相应节点写入K桶;如果相应桶已经达到了16个节点,则向桶中最早的节点发起挑战,挑战成功,将被挑战节点删除,将挑战节点加入K桶。K桶初始化完成后,进行节点发现流程。
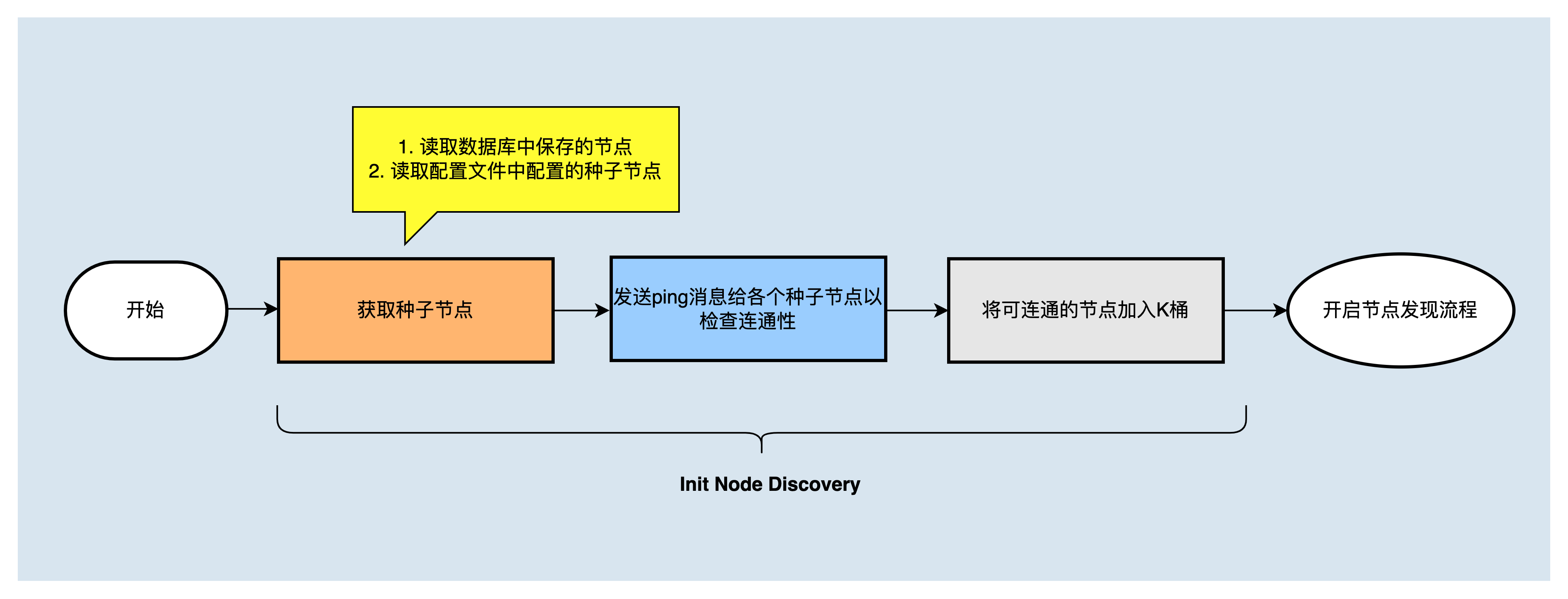
发送DISCOVER_FIND_NODE消息,发现更多节点¶
节点发现服务会开启两个节点发现定时任务(DiscoverTask和RefreshTask),周期执行节点发现过程来更新k桶。
-
DiscoverTask是发现更多距离自己近的节点,每30s执行一次,执行流程如下图所示: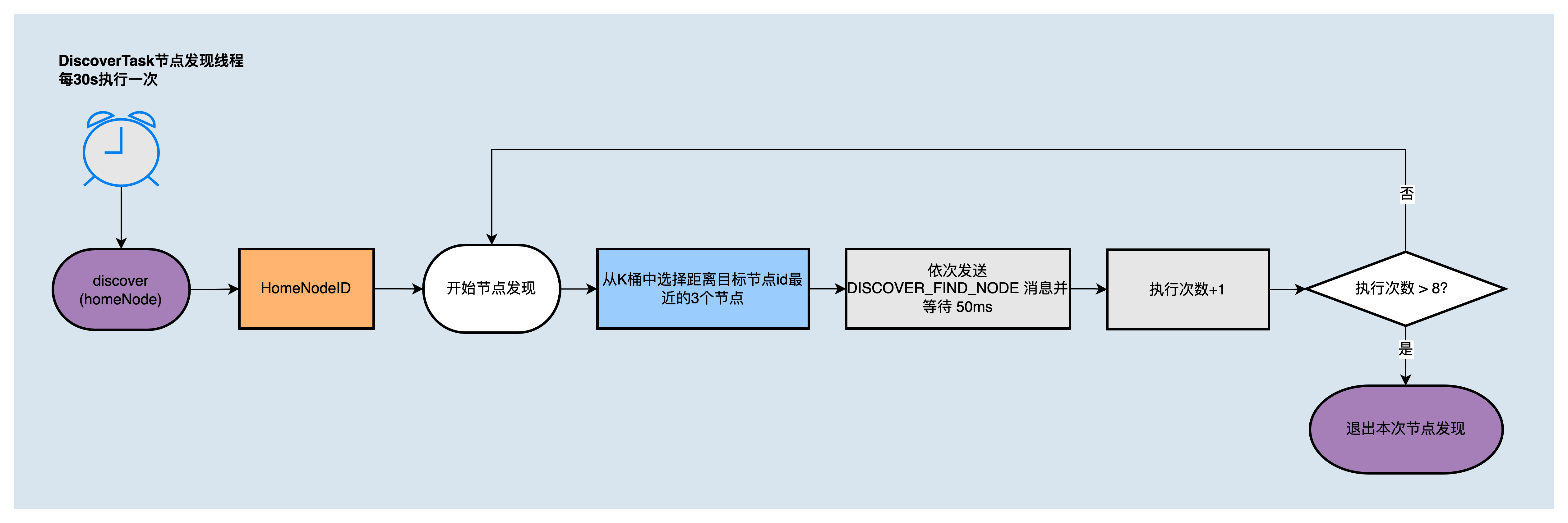
-
RefreshTask是通过随机节点ID来扩充本地k桶,即发现距离随机节点ID更近的节点,每7.2s执行一次,执行流程如下图所示: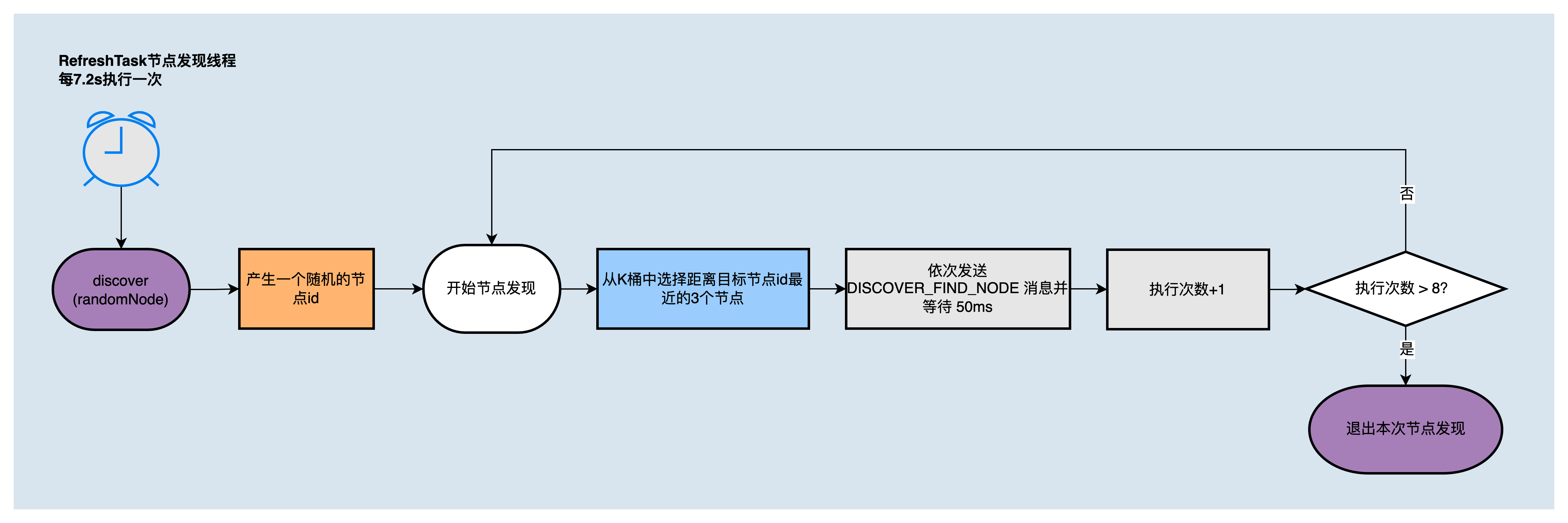
DiscoverTask和RefreshTask中使用的节点发现算法,在一次调用中会执行8轮,每轮向K桶中距离目标节点 ID 最近的3个节点发送 DISCOVER_FIND_NODE 消息,并等待回复。
接收到neighbors消息,更新K桶¶
当本节点接收到远端节点回复的 DISCOVER_NEIGHBORS 消息后,会依次向收到的邻居节点发送 DISCOVER_PING 消息,接下来如果收到了回复消息DISCOVER_PONG,则判断相应的K桶是否装满,如果K桶未满,则将新节点加入K桶,如果K桶满了,则向其中的某个节点发起挑战,若挑战成功(向被挑战的节点发送DISCOVER_PING 消息,如果未能收到其回复DISCOVER_PONG,则为挑战成功,否则挑战失败),则将旧节点从K桶中删除,将新节点加入K桶。
节点周期的执行节点发现任务,不断的更新K桶,构建自己的节点路由表。接下来就是节点间建立连接的过程了。
节点连接¶
在了解节点间如何建立TCP连接之前,您需要首先了解peer节点类型。
peer节点管理¶
节点需要对peer节点进行管理分类,以进行高效稳定的节点连接。远端节点可以分为如下几类:
- Active nodes:通过配置文件指定,系统启动后,会主动与其建立连接的节点。如果连接建立失败,则在每个TCP连接定时任务中都会重新尝试与其建立连接。
- Passive nodes:通过配置文件指定,被动接受连接的节点。
- Trust nodes:通过配置文件指定,Active nodes和Passive nodes都是trust nodes。当收到trust node的连接请求时,会跳过其它的条件检查,直接接受请求。
- badNodes:当收到异常的协议报文时,会将节点加入到badNodes,生效时长1个小时,当收到 badNodes 的连接请求,会直接拒绝请求
- recentlyDisconnectedNodes:当断开某条连接后,会把节点加入到recentlyDisconnectedNodes,有效时长30s,当收到 recentlyDisconnectedNodes 的连接请求,会直接拒绝请求
建立节点间TCP连接¶
在节点启动后,会创建一个建立节点间TCP连接的定时任务poolLoopExecutor,用于选择节点,并与之建立连接。建立TCP连接定时任务,工作过程如下:
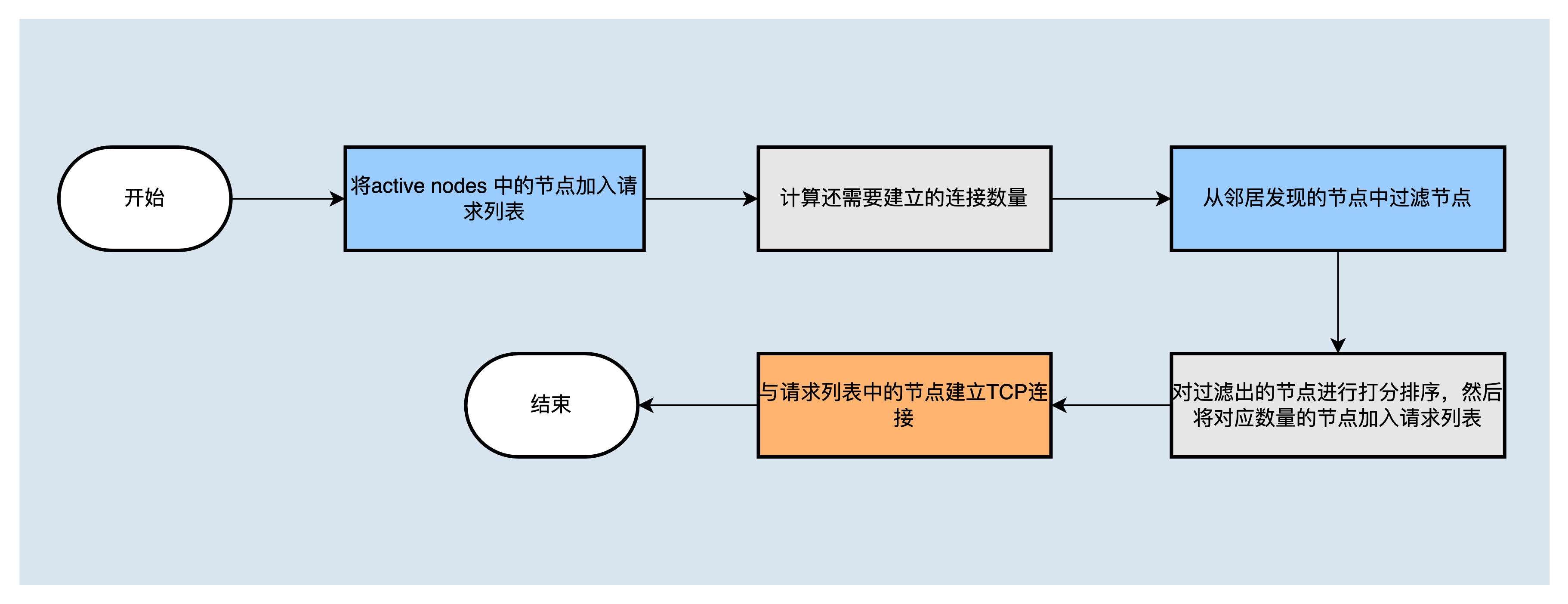
TCP连接主要分为两步:首先,确定要与之建立连接的节点的列表;列表中需要包含active nodes中还没有成功建立连接的节点,然后计算还需要建立连接的数量,从邻居发现节点列表里面根据 节点过滤策略 过滤出满足要求的节点,再根据 节点打分策略 对节点打分排序,将最高的相应数量的节点加入到请求列表中。最后,与请求列表中的节点建立TCP连接。
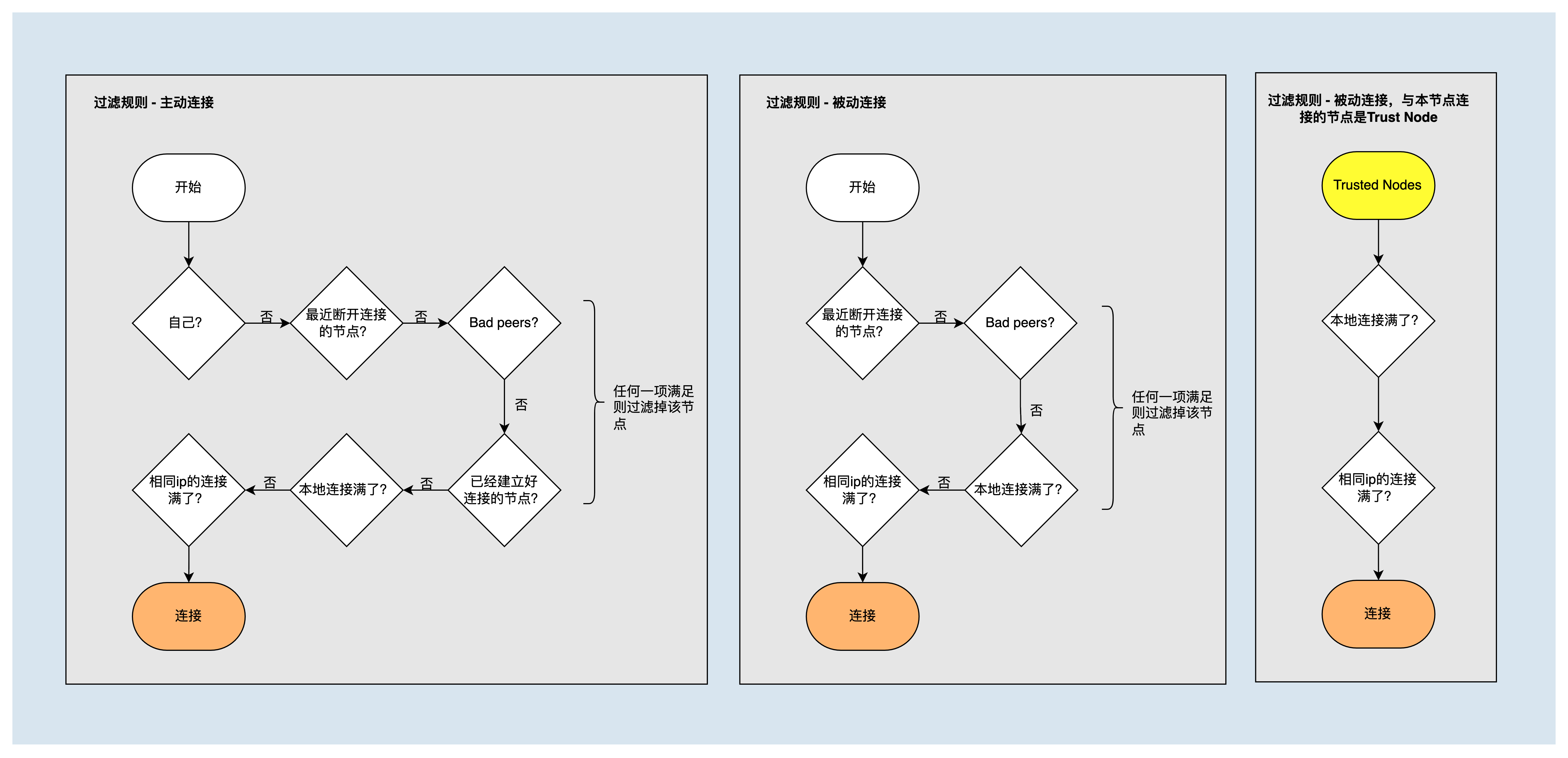
节点过滤策略¶
建立节点连接时,需过滤掉如下几类节点,并判断节点自己的连接数是否达到了最大连接。
- 自身节点
- recentlyDisconnectedNodes列表中的节点
- badNodes列表中的节点
- 已经建立了连接的节点
- 与该节点ip建立的连接数已经达到了上限值maxConnectionsWithSameIp的节点
但是对于可信节点,会忽略掉部分过滤策略,始终与其建立连接。
节点打分策略¶
节点分数用于确定建立连接的优先级,分数越高,优先级越高。打分维度包括:
- 丢包率:丢包率越低,说明数据通信质量越好。分数与丢包率成反比,最高分为100,最低为0
- 网络延迟:网络延时越小,说明网络质量越好。分数与平均网络延时成反比,最高分为20,最低为0
- TCP流量:TCP流量越大,说明通信比较活跃。分数与TCP流量成正比,最高分为20,最低为0
- 断开连接次数:断开连接次数越少,说明节点越稳定。断开连接分数为负数,且与断开连接次数为正比,值为断开连接次数的10倍
- Handshake:曾经handshake成功过的节点,表示有相同的区块链信息,因此优先选择和他们建立连接。Handshake成功次数大于0时,Handshake得分为20,否则得分为0
- 处罚状态:处于处罚状态的节点,分数为0,不参与其它维度打分,包含以下几种情况:
- 节点断开连接时间不到60s
- 节点在badNodes列表中
- 区块链信息不一致
计算节点分数时,首先判断节点是否为处罚状态,如果是,则分数计为0,否则,节点分数为各个维度的得分之和。
握手¶
TCP 连接建立成功后,主动发起TCP连接请求的节点,会向邻居节点发送握手消息 P2P_HELLO,目的为了确认节点间的链路信息是否一致,以及是否需要发起区块同步流程。
当邻居节点收到 P2P_HELLO 后,会与本地信息做比较,比如检查p2p version、创世块信息是否一致,若一致,还需要检查固化快,以及判断是否是重复的连接、恶意节点等。若所有的检查条件都通过,则会回复P2P_HELLO消息,然后进行区块同步或广播;否则,断开连接。
信道保活¶
信道保活是通过 P2P_PING、P2P_PONG TCP报文来完成的。当节点与邻居节点建立了TCP连接并握手成功后,节点会为连接开启一个线程 pingTask 定期发送 P2P_PING 消息以维护该TCP连接,每10s调度一次。如果在超时时间内未收到节点回复的 P2P_PONG 消息,则断开连接。
区块同步¶
在与对方节点完成握手后,如果发现对方节点的区块链比本地的区块链要长,根据最长链原则,会触发区块同步的处理流程syncService.startSync。同步过程中的报文交互如下图:
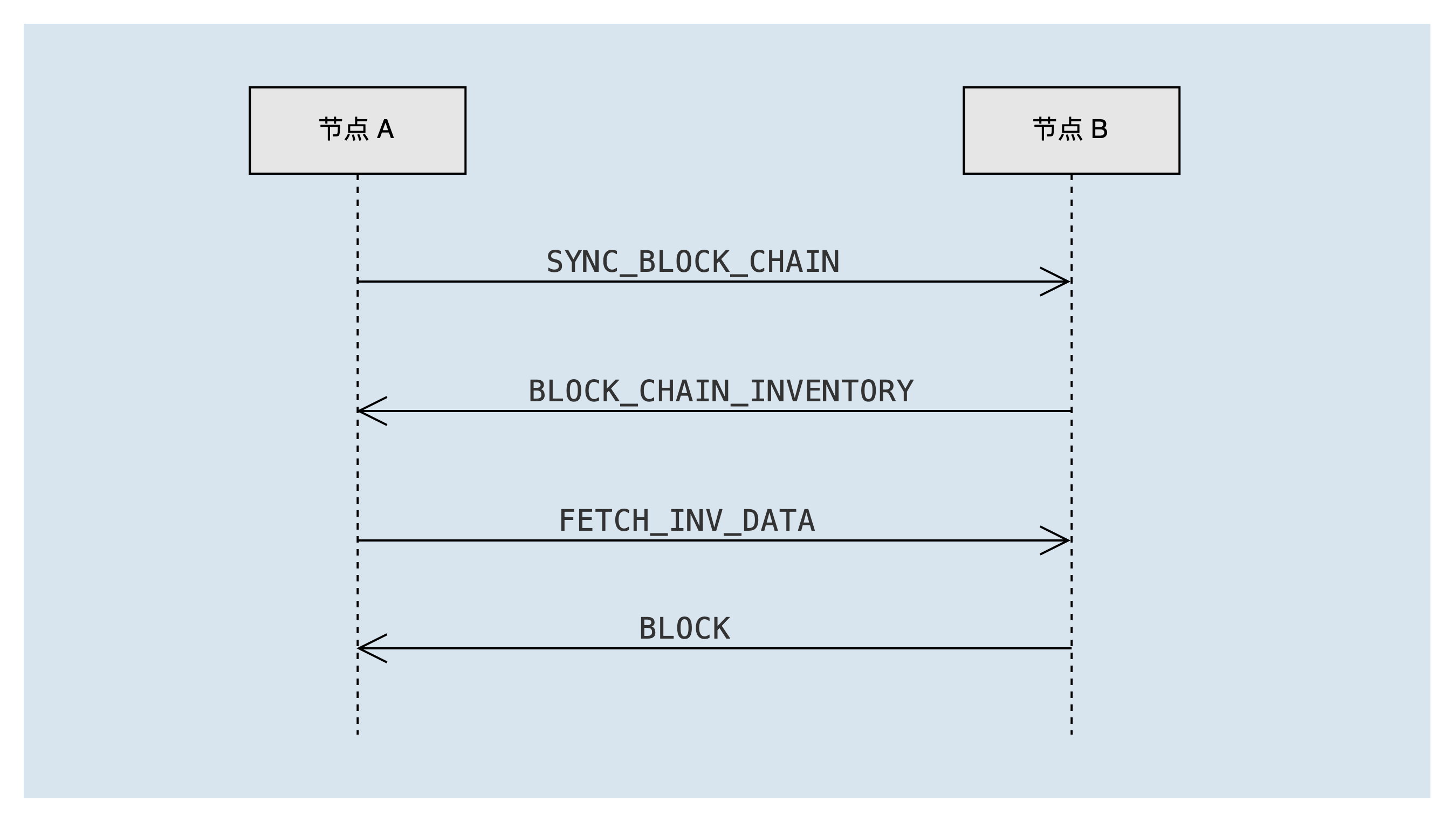
节点A向对方节点B发送 SYNC_BLOCK_CHAIN 消息,以宣告本地链的摘要信息。对方节点B收到后,计算出节点A缺失的区块清单,并将缺失区块的id列表通过 BLOCK_CHAIN_INVENTORY 消息发送给节点A,一次最多携带2000个区块id。
节点A收到 BLOCK_CHAIN_INVENTORY 消息后,取出缺失区块id,并通过异步的方式向节点B发送 FETCH_INV_DATA 消息以请求缺少的区块,一次最多请求100个区块。如果还有需要同步的区块(即 BLOCK_CHAIN_INVENTORY 报文中的remain_num大于0),会触发新一轮的区块同步流程。
节点B收到节点A的 FETCH_INV_DATA 报文后,通过 BLOCK 消息将区块发送给节点A。节点A收到 BLOCK 报文后,异步处理该区块。
链摘要及缺失区块清单¶
下面根据几个不同的区块同步场景示例,说明链摘要和节点缺少的区块清单的生成。
- 链摘要:有序的区块blockID列表,包括:最高固化块、最高非固化块,以及之间二分法对应的区块
- 缺失区块清单:邻居节点根据链摘要与自己链进行比较,确定对方缺失的区块清单,返回一组连续的区块blockID以及剩余的块数
普通场景¶
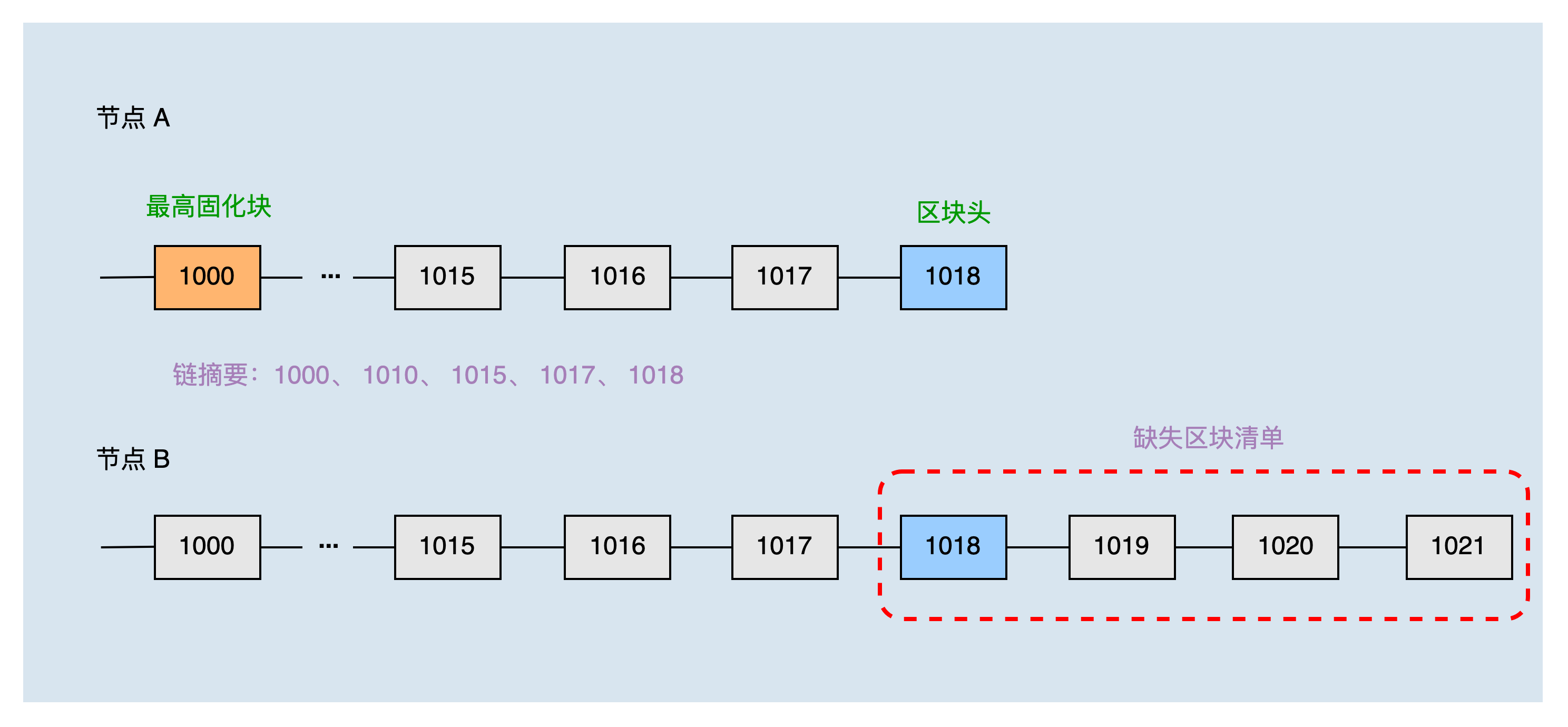
本地头块高度为1018,固化块高度为1000,两个节点刚建立连接,所以共同块高度为0,通过二分方式获取到节点A的本地链摘要为:1000、1010、1015、1017、1018。
节点B收到节点A的链摘要后,结合本地链可以生产节点A缺少的区块清单为:1018、1019、1020、1021。之后节点A根据缺失区块清单,请求同步区块1019、1020、1021。
切链场景¶
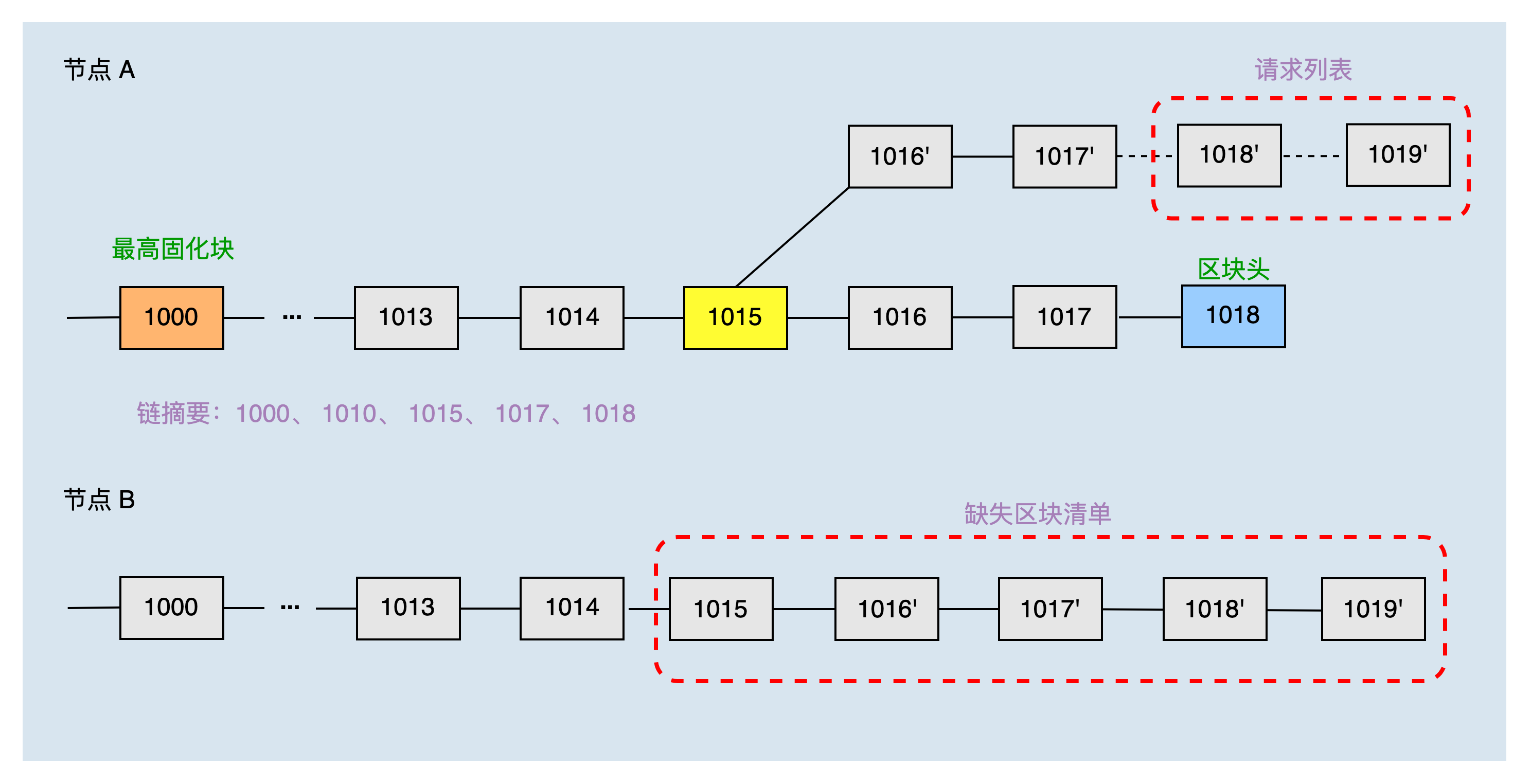
本地主链头块高度为1018,固化块高度为1000,两个节点刚建立连接,所以共同块高度为0,通过二分方式获取到节点A的本地链摘要为:1000、1010、1015、1017、1018。
节点B收到节点A的链摘要后,发现本地主链跟节点A的主链不在同一条链上,对比节点A的链摘要,找到共同块高度为1015,则认为节点A缺少的区块清单为:1015、1016'、1017'、1018',1019'。之后节点A根据缺失区块清单,请求同步区块1018',1019'。
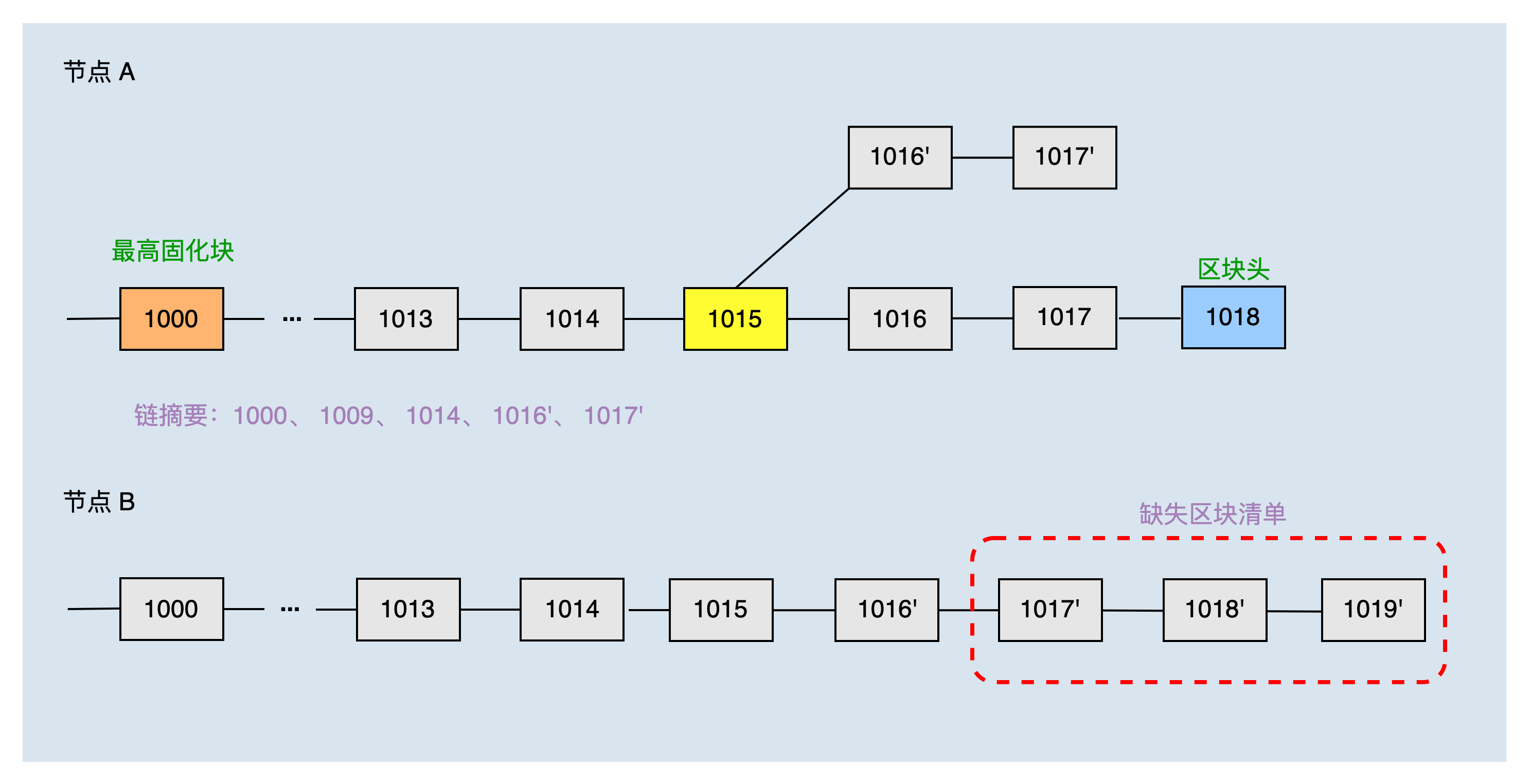
另一种切链场景,本地主链头块高度为1018,固化块高度为1000,共同块为1017‘,位于fork链上,通过二分方式获取到节点A的本地链摘要为:1000、1009、1014、1016'、1017'。
节点B收到节点A的链摘要后,结合本地链可以生产节点A缺少的区块清单为:1017'、1018'、1019'。之后节点A根据缺失区块清单,请求同步区块1018',1019'。
区块和交易广播¶
当超级代表节点生产出新的区块,或者全节点接收到用户发起的新交易时,会发起交易&区块广播流程。当节点接收到新区块或者新交易时,会转发相应的区块或交易,转发与广播的流程一样。报文交互如下图所示:
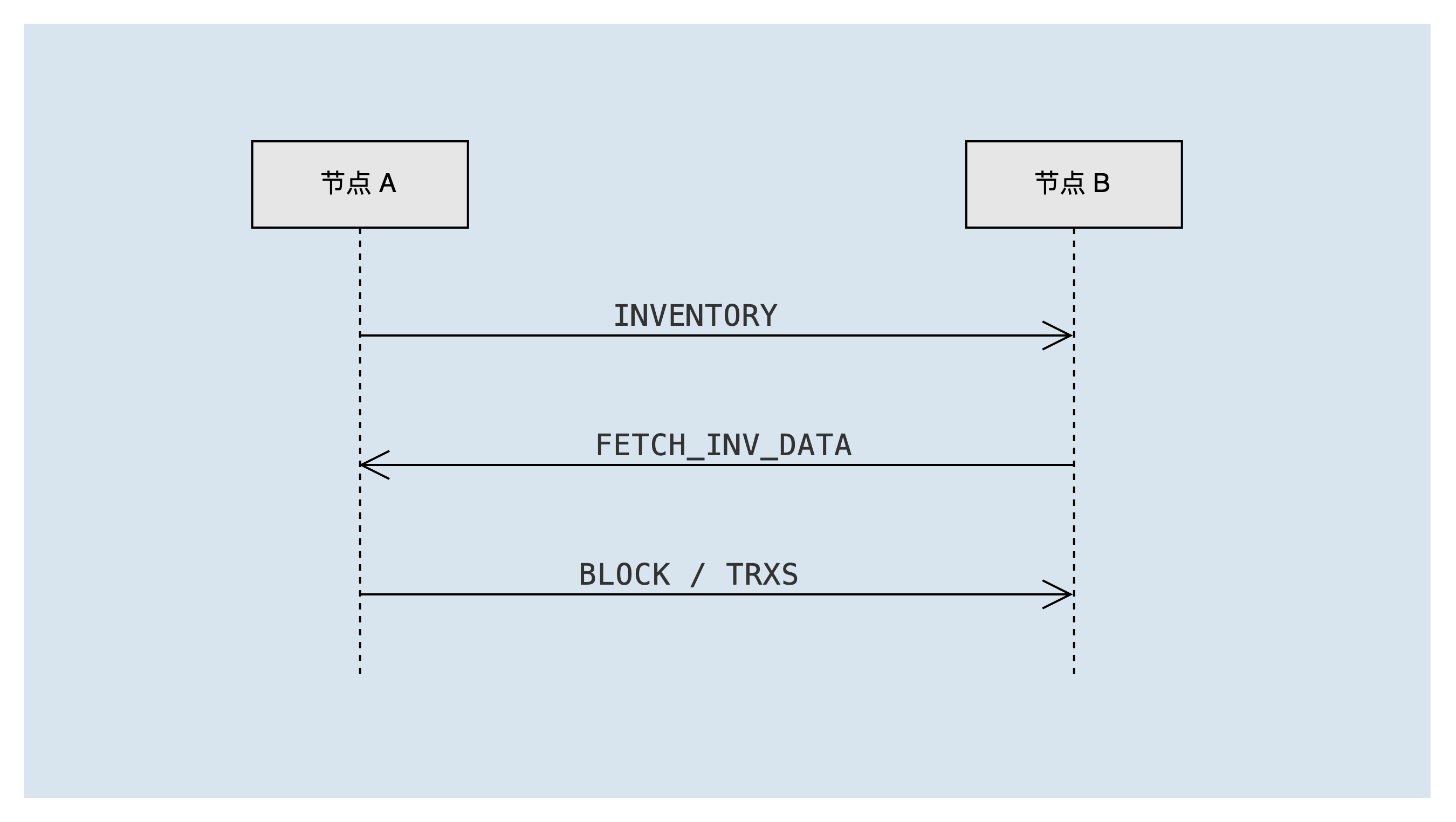
其中涉及到的消息类型包括:
INVENTORY- 广播清单:区块或者交易id列表FETCH_INV_DATA- 请求需要获取的清单数据:区块或者交易id列表BLOCK- 区块数据TRXS- 交易数据
节点A将待广播交易或区块通过 INVENTORY 清单消息发送到节点B。节点B收到 INVENTORY 清单消息后,需要检查对方节点的状态,如果可以接收该消息,则将清单中的区块/交易放入待获取队列 invToFetch 中。如果是区块清单,还会立即触发"获取区块&交易任务",来向节点A发送 FETCH_INV_DATA 消息获取区块&交易。
节点A收到 FETCH_INV_DATA 消息后,会检查是否发送过清单消息给对方,如果发送过,则根据清单数据,向节点B发送交易或者区块消息。节点B收到交易或者区块消息后,处理消息,并触发转发流程。
总结¶
本文介绍了TRON最底层模块-P2P网络相关的实现细节,包括节点发现、节点连接、区块同步、区块和交易广播流程,希望通过阅读本文能帮助开发者进一步了解和开发java-tron网络相关模块。