ChainBase 深入解析¶
概览¶
众所周知区块链本质上是一个不可篡改的分布式账本,非常适合解决信任的问题,现实中往往利用区块链来进行记账和交易,比如很多应用采用 BTC、ETH、TRX 等数字货币来进行经济活动以保证资金的公开透明。
而实现这样一个不可篡改的分布式账本是一个非常复杂的系统工程,涉及到很多技术领域:比如 p2p 网络、智能合约、数据库、密码学、共识机制等。其中数据库作为底层存储的基础,各个区块链团队都在探索数据库层面的设计与优化。
java-tron 的数据库模块也称为ChainBase 模块,本文主要介绍一些背景知识,并通过介绍交易处理、状态回滚、数据持久化等逻辑为开发者展现ChainBase 模块的实现细节。
预备知识¶
数据库是区块链系统中重要的一环,它存储了区块链上的所有数据,是区块链系统正常运行的基础,每个全节点都保存了一份全量的数据,包含区块数据和状态数据,java-tron 采用 Account 模型来保存用户的账户状态。
账户模型¶
目前主流的账户模型有两种:
- UTXO模型
- Account模型
UTXO 模型是无状态的,能更容易并发处理交易,并且拥有较好的隐私性,但在编程灵活度方面有所欠缺。
Account 模型中用户数据都存放在对应的账户中,并且智能合约也以代码的形式存放在 Account中,这种模型更加直观,开发人员更容易理解。出于可编程性,灵活性等方面的考虑,java-tron 采用了 Account 模型。
共识¶
目前主流的共识有 PoW、PoS、DPoS 等。PoW 即工作量证明,所有节点都参与计算一个预期的 hash 结果,优先计算出结果的节点拥有出块的权利,但是随着算力不断增长,计算 hash 所需的能耗也在不断增大,而且大矿场垄断了大部分的算力,这也违背了去中心化的初衷。
为了解决 PoW 所面临的问题,有人提出了PoS(Proof of Stake),简单理解为:持币越多的节点获得出块权利的概率就越大,但这样会导致垄断问题,所以又对 PoS 进行了改进,提出了 DPoS(Delegated Proof of Stake):通过选举出的超级代表来保证去中心化特性,同时超级代表轮流负责出块来提高了出块的效率。java-tron 目前采用 DPoS 共识机制。
更多细节可参看:Delegated Proof of Stake
持久化存储¶
区块链业务和传统互联网业务存在一定的区别,区块链业务在数据库层面并没有特别复杂的处理逻辑,但区块链中存在大量key-value的读写操作,所以对数据的读写性能有着较高的要求。
基于这方面的考虑,java-tron 默认采用 LevelDB 作为底层数据存储(在 ARM64 架构下会强制使用 RocksDB 并忽略配置,因为 LevelDB 在 ARM 上已废弃),并且 java-tron 有着良好的架构设计,采用面向接口编程的模式使得 chainbase 模块拥有着较好的扩展性,任何实现了 chainbase 接口的数据库都可以作为 java-tron 的底层存储引擎,比如在 chainbase v2 版本中提供了基于 RocksDB 的数据库实现。
交易验证¶
众所周知区块链中主要存储的是交易数据,介绍 chainbase 模块前需要首先了解 java-tron 中交易的处理逻辑。
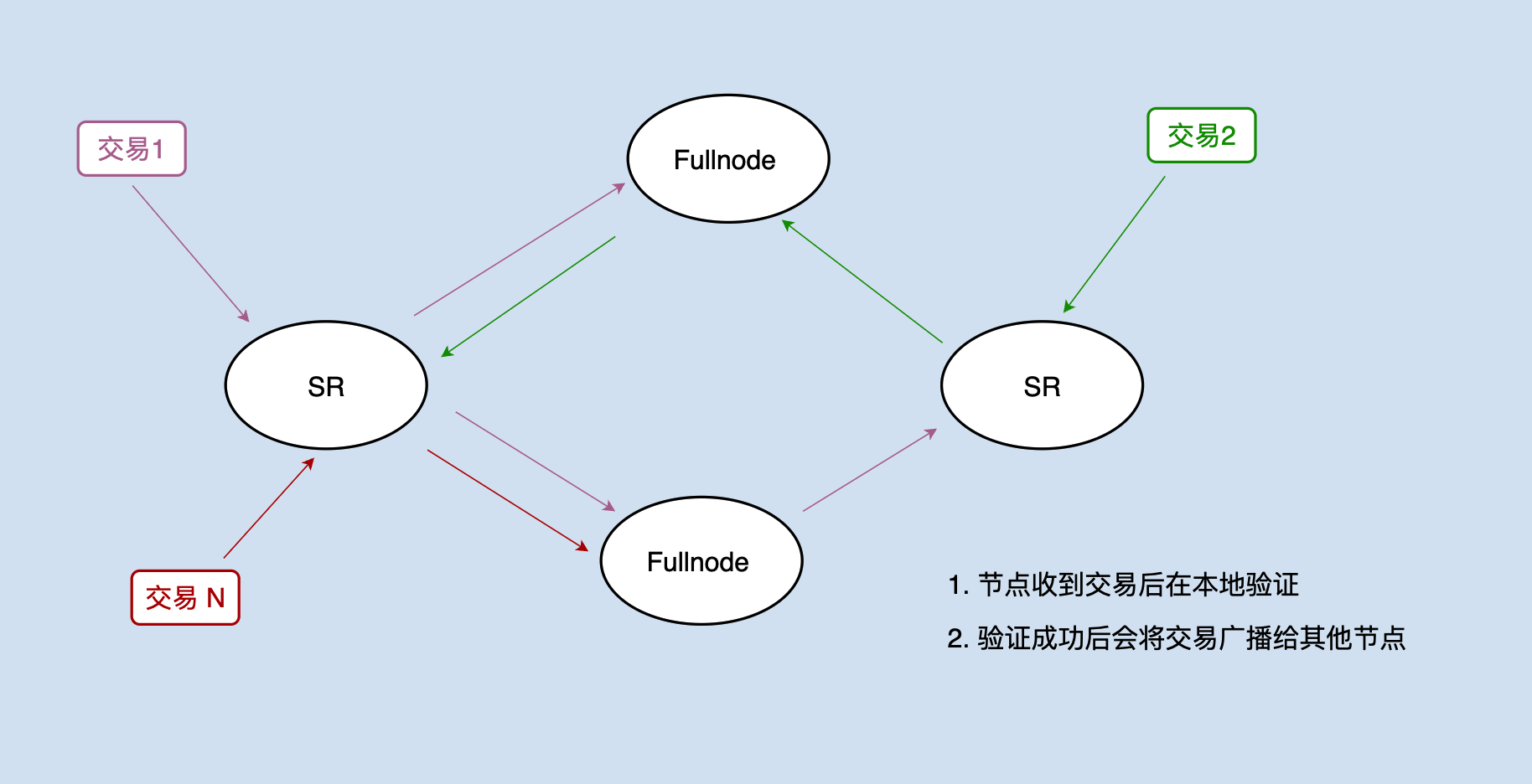
交易会通过网络广播分发到各个节点,节点接收交易后,首先会对交易的签名做校验,验证成功后还需要对交易进行预执行,以此来判断该交易是否合法。
注:java-tron 的具体实现和上图有所偏差,同时为了方便起见,本文将 FullNode 节点和 SR 统称为节点。
比如处理一笔转账交易:用户A向用户B转账100个 TRX,需要验证用户A是否有足够的余额来进行转账。
数据库中的 account 库保存了所有用户的账户信息,包括用户的余额信息,那如何判断这个转账交易是否合法?java-tron 的逻辑是:当从网络中接收到交易后,会立即执行该交易操作,即在本地的数据库中将账户信息进行修改:(accountA - 100TRX,accountB + 100TRX)。假如这个操作能够执行成功,那么说明至少在当前状态下这个交易是合法的,可以打包至区块中。
名词解释¶
SR:超级代表(Super Representative),负责产块
FullNode:全节点,存储全量区块数据,负责交易、区块的广播和校验,并提供查询服务
TRX:波场原生代币
状态回滚¶
上面我们讲到java-tron通过预执行来验证交易是否合法,但我们需要知道的是该交易在某个节点上验证成功并不代表该交易已成功上链,因为该交易并未打包到已共识的区块中,存在被回滚的风险。
java-tron 的共识遵循了一个原则:即超过2/3个超级代表认同的区块中的交易才是真正成功上链的交易。也可以理解为:
- 交易被打包进入区块
- 该区块被超过2/3个 SR 所接受
满足上述两点的交易才是成功上链的交易。java-tron 中一个交易被最终确认需要经历三个阶段:
- 交易校验
- 交易打包进区块
- 该区块被网络大部分节点接收、应用并最终固化
这也就引出了一个问题:在 java-tron 的实现中,一个节点如果对交易做验证后,它的数据库状态随之进行了改变,假如这个交易最终并未打包进区块或该区块并未满足超过2/3个 SR 接受,那这个节点的状态和整个网络的状态就会不一致。
所以除了处理被超过2/3个SR认可的区块中的交易数据外,其余所有对交易做处理而产生的数据状态的变化都有可能需要回滚。而且需要回滚的情况不止一种,总共三种:
- 接收到新的区块后,回滚交易验证产生的状态变更
- 生产区块后,回滚交易验证产生的状态变更
- 若发现分叉链,回滚分叉链中区块的交易产生的状态变更
这3种情况造成的数据状态变化都有可能需要回滚。下面依次讲解为何这三处需要回滚。
接收新区块后的状态回滚¶
在接收到新的区块时,节点需要回滚到上个区块的结束时状态,回滚掉所有之后验证的交易。如下图所示:
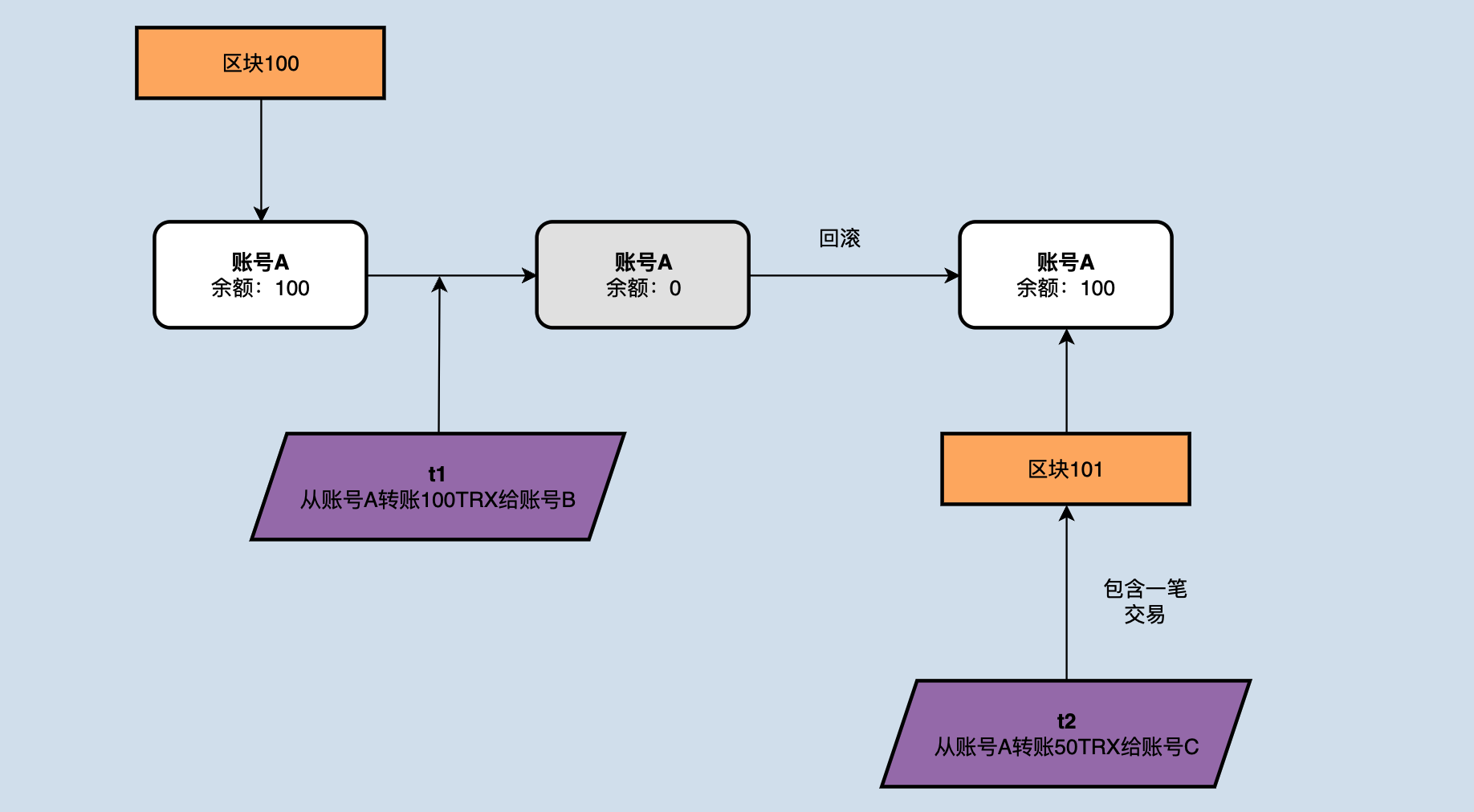
假如节点在区块高度为1000时 accountA 账户余额为100,此时接收并校验了一个转账交易t1,并将自己的100TRX转账给了 accountB,当接收到了新的block1001后,该block包含了一个 accountA 转50TRX给 accountC 的交易t2,理论上t2已经打包进区块,优先级是要优于t1,但是如果不做任何操作的话,t2的校验将无法通过,因为 accountA 没有足够的余额,所以在接收到新的区块1001后,需要将交易t1所产生的的状态变更进行回滚。
生产区块后的状态回滚¶
首先读者可能会有一个疑问:已经验证过的交易直接打包到区块中即可,也不会对数据库状态造成改变,为何还有数据库状态的变更?
因为java-tron 在将交易打包到区块时对交易做了二次校验,做二次校验是因为交易的时效性问题,依然以上图为例,图中可以得知在接收到区块1001后对交易t1进行了回滚,并且将 accountA 的余额减去50,之后轮到该节点打包出块,但是此时t1已经变成一个非法的交易,因为 accountA 中的余额已经不够支付100个TRX,直接将t1打包进区块必然不可取,所以需要对交易再次进行校验,这也就是在区块打包时依然需要对交易做二次校验的原因。
而区块打包成功后,该节点会将向网络广播该区块,同时也在本地 apply该区块,而 apply 的逻辑则会对区块中的交易再次校验,所以在打包完区块后仍然需要执行回滚操作。
分叉链的状态回滚¶
这是最后一种回滚的情况,区块链不可避免的会出现分叉的情况,尤其是基于 DPoS 这种出块速度较快的区块链系统更容易出现分叉的情况。
java-tron 在内存维护了一个如图所示的数据结构:
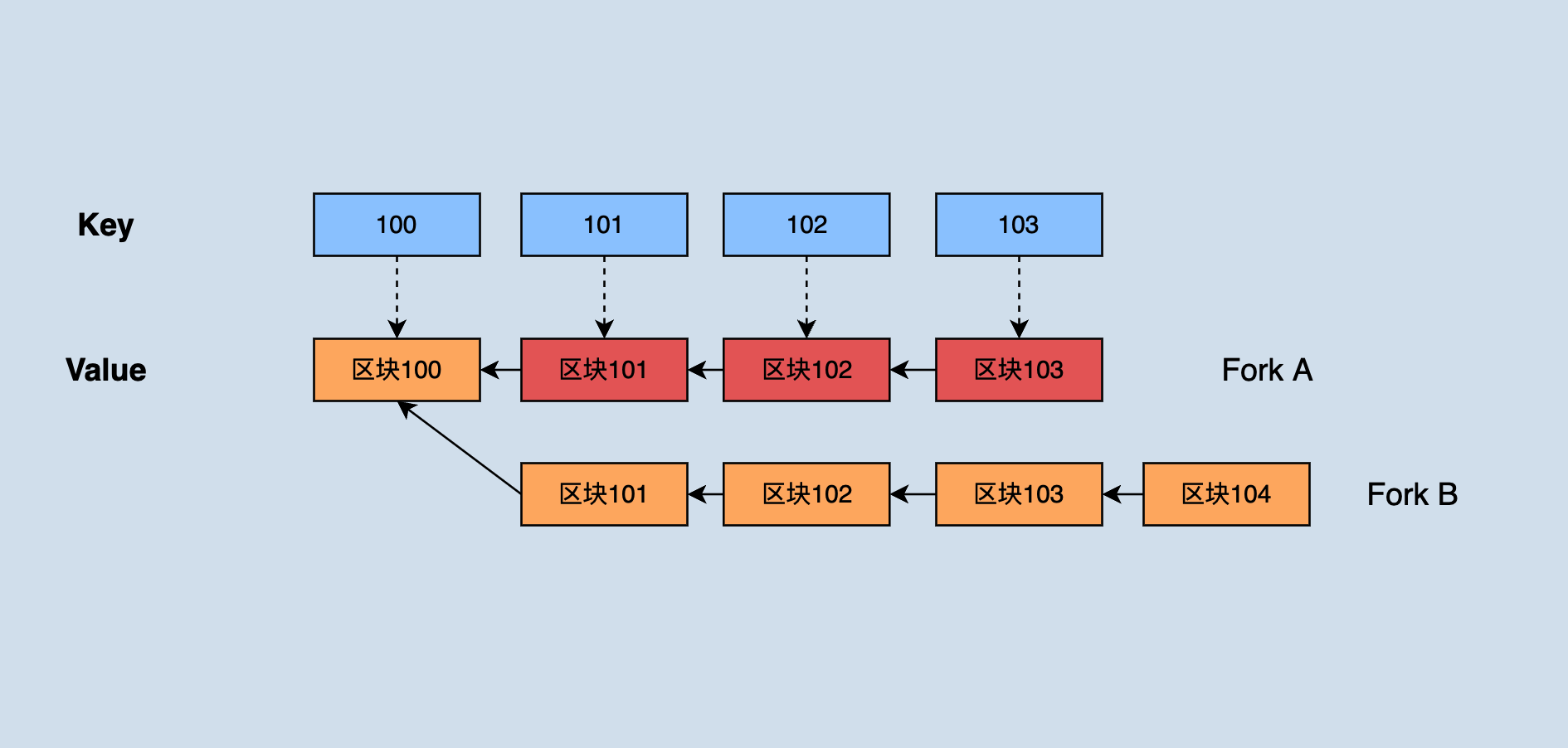
java-tron保存了最近还未达成共识的所有区块。当出现分叉链时,根据最长链原则:假如分叉链的区块高度大于目前主链区块高度,则需要将分叉链切换成主链,切换时就需要回滚掉之前主链上的一部分区块直到它们共同的父区块,然后从该父区块处依次 apply 新的主链区块。
如图,深色部分的 fork A 原先为主链,由于fork B 的高度不断增长最终超过了 A 的高度,此时就需要回滚掉 fork A 中高度为1003、1002、1001的三个区块数据,然后依次 apply fork B 中 1001'、1002'、1003'、1004'区块。
状态回滚实现¶
本章节从代码的角度讲解接收交易、交易验证、生成区块、验证区块、保存区块,来更进一步解析java-tron的chainbase模块。如没有特殊声明,则默认描述的为Fullnode(包含SR)的逻辑。
交易接收¶
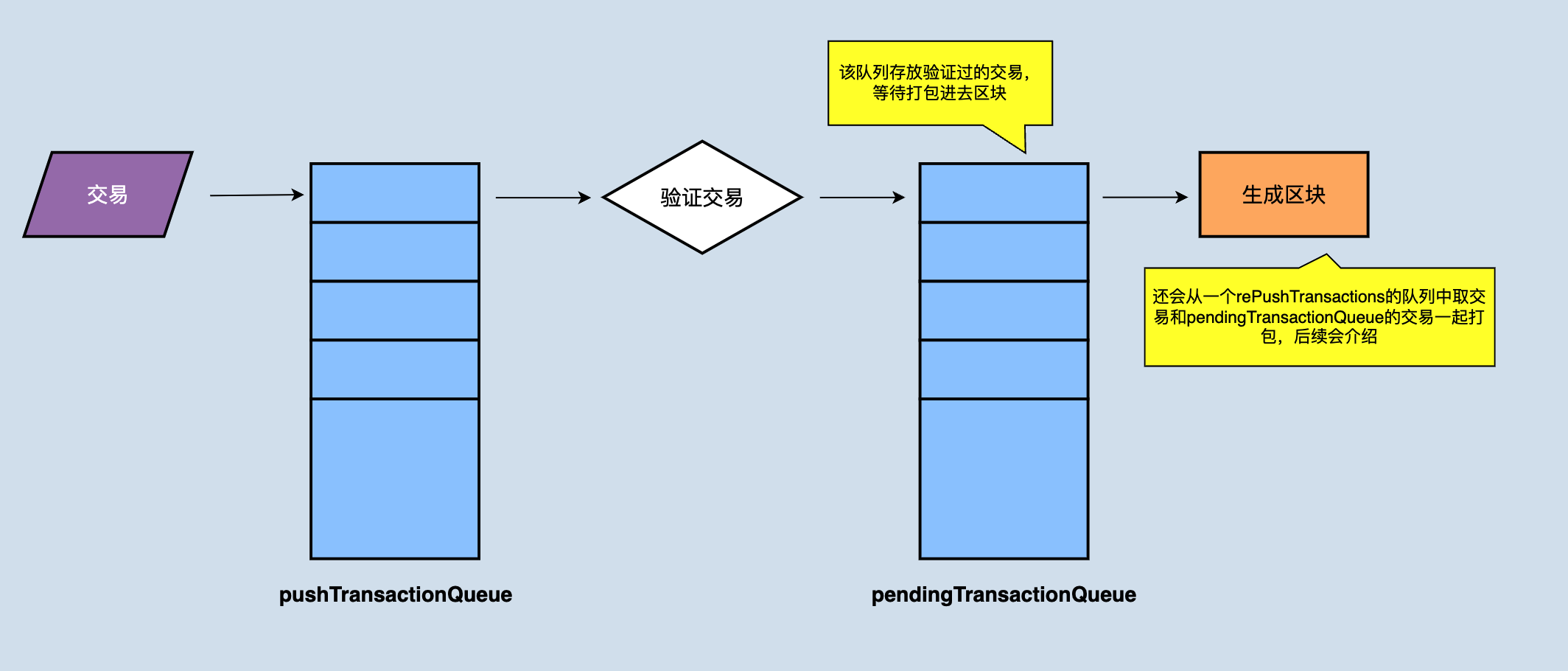
节点收到广播过来的交易后,通过调用Manager类的pushTransaction(final TransactionCapsule trx)函数将交易放到本地的pushTransactionQueue缓存队列,同时对该交易进行验证,此方法的返回比较考究:
- 如果验证成功直接返回true
- 对于用户通过API向节点发送的交易,交易验证失败,会抛出异常,用户会拿到异常信息。对于节点通过P2P网络从其他节点接受到的交易只会将异常记录在本地。
交易验证成功之后,没有问题的交易会放入pendingTransactionQueue,pendingTransactionQueue负责在生成区块时提供交易集合。如果节点为SR节点时,当轮到到它产块时,就从pendingTransactionQueue中拿出来全部或者部分(取决于pendingTransactionQueue中有多少交易)来生成一个区块。
收到新区块时的状态回滚¶
节点在收到新区块前也会收到交易广播或收到来自其他节点的交易广播,需要对接收到的交易进行验证来判断该交易是否能正确的执行,验证也就意味着需要改变状态,而验证成功的交易并不代表这个交易就一定能最终执行,还要再经过打包进区块和固化的过程,这步可以认为是提前先筛选掉那些明显错误的交易,这里只是验证。 所以新的区块到来时这些交易验证所产生的状态都是应该被回滚掉的;apply 区块时产生的状态变更不会在这一步(收到新区块时清理 pending 交易)被回滚,但在区块固化之前,其 applied 状态仍可能在 fork 切换时被回滚。
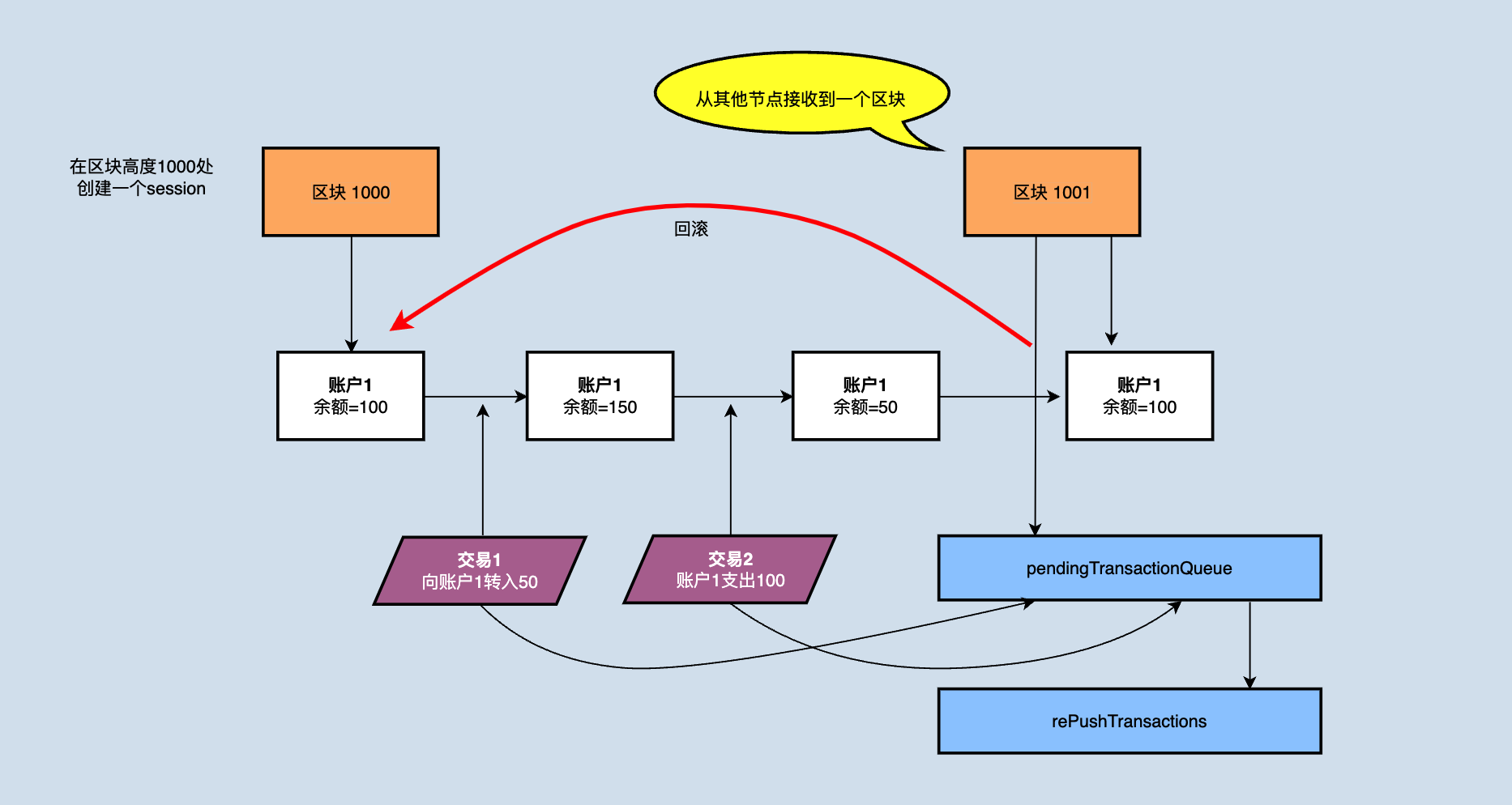
回滚时需要将pendingTransactionQueue中的交易挪至rePushTransactions,并清空pendingTransactionQueue,详细解释看图。
为什么新的区块到来后需要清空pendingTransactionQueue?首先明确一点,pendingTransactionQueue队列负责在生成区块时提供交易数据,也就是说存放的是验证过的可以直接打包进区块的交易,但是因为新的区块也会对账户状态进行变更,可能pendingTransactionQueue里面之前验证没问题的交易在apply新的区块后验证不通过(最简单的例子:新区块某笔交易是账户A花费了一部分token,导致账户A在队列中的某笔交易金额不够支付了)。将交易挪至rePushTransactions后会有后台线程专门负责对该队列中的交易再次验证,如果没有问题就再次放进pendingTransactionQueue,为产生区块提供数据。
java-tron中存在一个session对象,一个session表示的是一个区块对状态的变更,session对象主要用来回滚,比如将状态回滚到上一个区块的状态都需要通过session来操作,如下图所示:
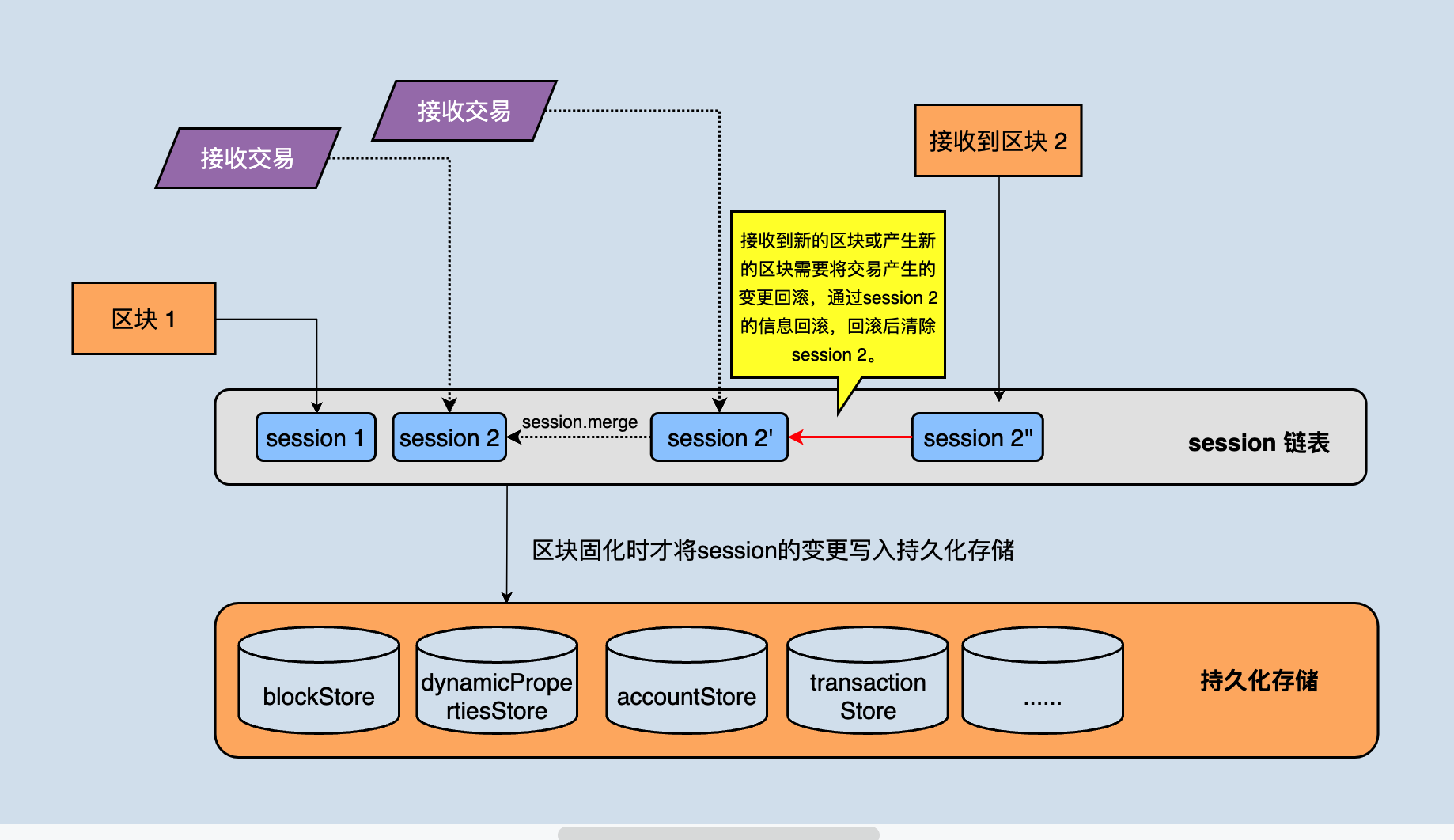
上图图中能看到持久化存储中有很多不同类型的数据库,就是这些数据共同组织成一个完整的区块链,比如区块存储在 khasodb 和 blockStore 中,账户信息存储在 accountStore 中....
节点维护了一个 session 链表,该链表存储的是区块/交易对应的变更信息,节点可以通过这些变更信息进行回退。上图中 session1 是当前最高区块的对状态的变更,当次接收到一个交易后会产生一个新的 session2 ,后续接收一个交易都会产生一个临时的tmpSession,该交易验证后,tmpSession立马合并到session2中,再次接受到一个新区块之前,所有的交易验证产生的状态变更都会保存在 session2 中,当有新区块到来时,直接执行 session2 的 reset 方法即可将状态回滚到上个区块。
生产区块时的状态回滚¶
SR生产区块前需要回滚,原因比较复杂,我们先考虑一个场景:
- pendingTransactionQueue 中存放是当前已经验证过的交易,所以某SR节点产块时只要直接打包pendingTransactionQueue 中的交易进区块,打包完之后将状态回滚到上一个区块的状态即可。
但是这种方案存在一个问题:假如该 SR 节点刚刚接收并 apply 一个新的区块,从前面的内容可知 pendingTransactionQueue 将被清空至rePushTransactions,此时正好轮到这个 SR 打包区块了,但 SR 的 pendingTransactionQueue 中没有什么交易。所以真正的实现是,产块时不止从 pendingTransactionQueue 读取交易,如果 pendingTransactionQueue 中交易较少时,还会从 rePushTransactions 中读取交易来放进区块,而通过上面的分析可知 rePushTransactions 中的交易有可能已经不能通过了,所以需要对交易再次进行验证。而正是因为有这个验证逻辑,才需要在出块前先将状态回滚。
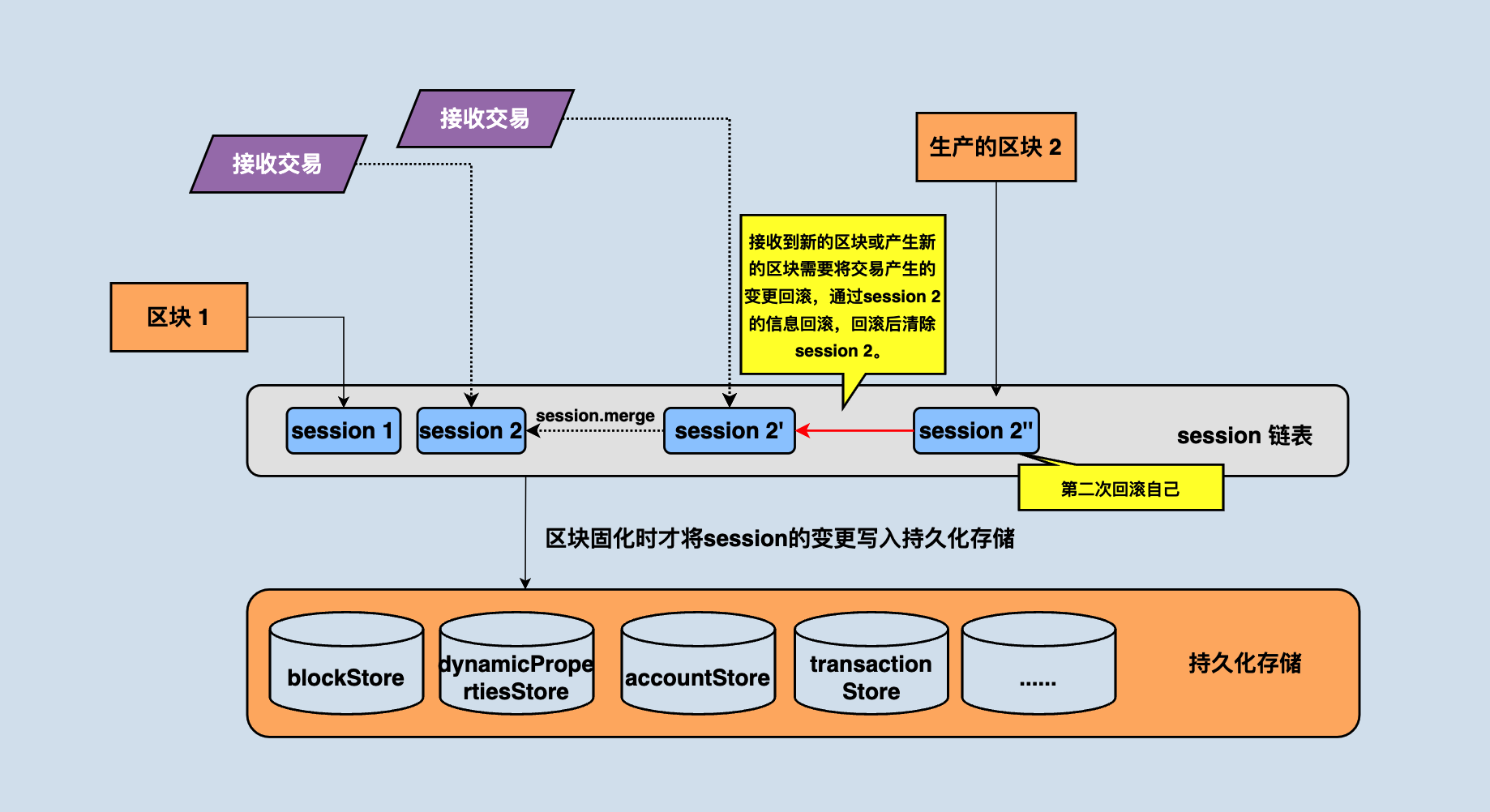
生产区块的过程中会对交易再次验证,所以会产生状态变更,但这是只是区块生成, 还需要广播区块,由广播接受到的区块会真正的改变状态,所以生成区块所产生的状态变更也需要被回滚掉。如上图所示,当区块生产完成后, 还需要将session2'' 回滚掉。
区块持久化¶
java-tron采用的是 DPOS 共识机制, java-tron 的 DPOS 是投票选出来27个节点当出块节点(也称为SR),SR有出块的权利和义务,并且被超过2/3个SR认可的block即为已经达成一致意见的区块,这些区块不能再被回滚,也称为固化块。非固化块的状态会先写入可回滚的内存 snapshot 层(session),只有已固化的 snapshot 层才会被 flush/merge 到持久化存储,
java-tron中 SnapshotManager 是存储模块的关键入口,持有了当前所有业务数据库的引用,并将数据库引用存储在一个列表中。每个数据库实例都支持在自身的基础上新增一层状态集:SnapshotImpl,SnapshotImpl 是一个内存 HashMap,多个 SnapshotImpl 通过链表形式关联,一个 SnapshotImpl 保留一次状态变更所涉及的数据修改,且 SnapshotImpl 之间相互独立,通过这种数据结构来将每个状态独立开,如下图所示:
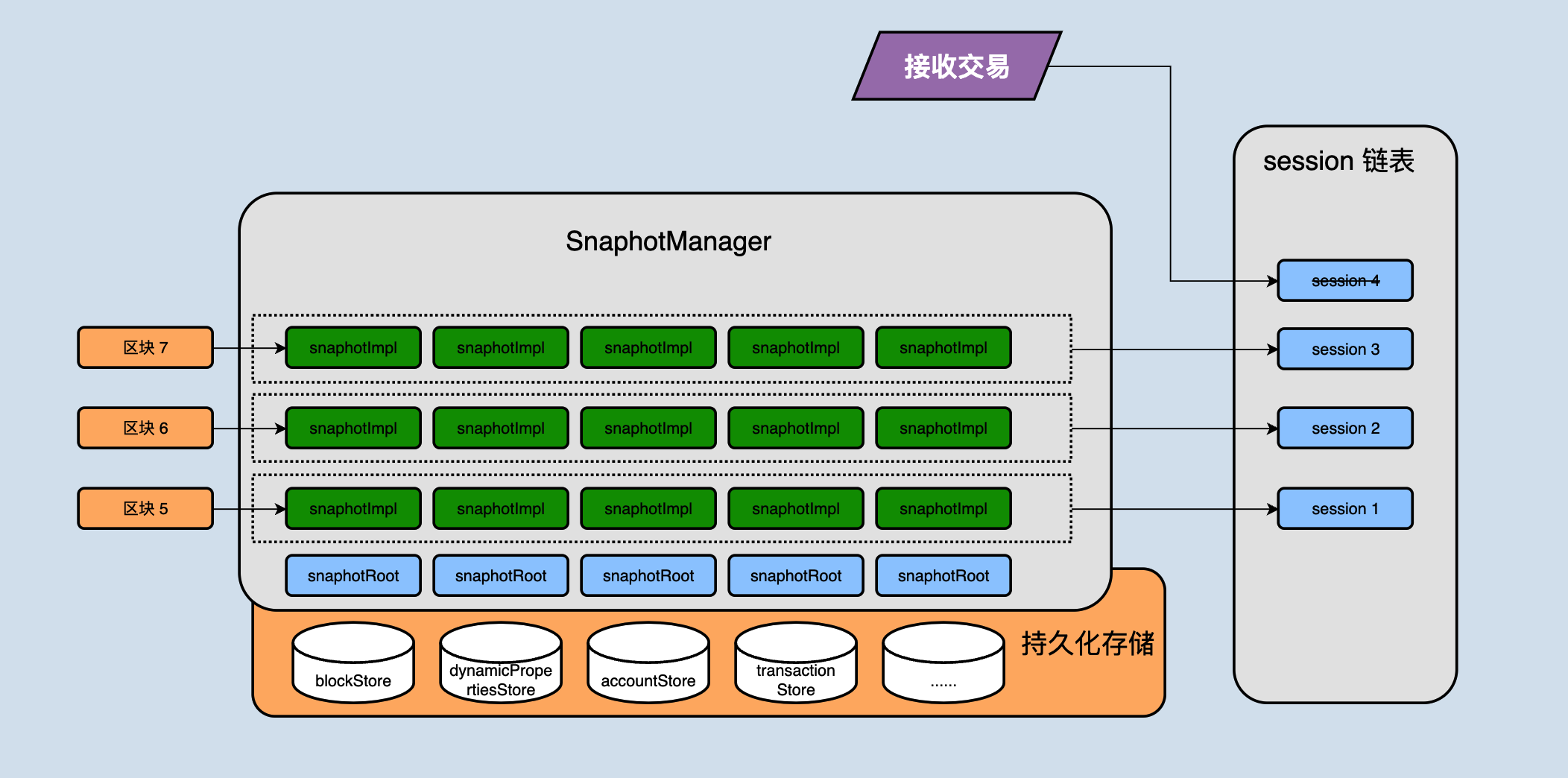
上图中 SnapshotRoot 是对持久化数据库的封装类,负责存储已固化的数据。
前面的章节中我们讲到session,一个session表示的是一个区块对状态的变更,实际上一个session包含了各个数据库对应SnapshotImpl,比如上图中区块5这一层所有的 SnapshotImpl 共同构成了区块5对整个数据库的变更。
节点接收到新区块后产生的变更不会直接存储到持久化存储中,而是首先存在 snapshotImpl 中,每接收一个区块对应产生一个snapshotImpl 不断的接收区块会导致 snapshotImpl 越来越多,什么时候会写入到持久化存储中呢?
SnapshotManager 中存在两个变量:size 和 maxSize,size 此处我们简单理解为目前内存中有多少层 snapshotImpl,maxSize 则表示目前固化块和最新块高度的差值。
这样就很明显了,如果 size > maxSize,那么说明最开始的 size-maxSize 层的snapshotImpl 对应的区块已经是固化块了,它们可以落盘了,然后会将应该落盘的 snapshotImpl 合并到持久化存储中,这样来确保 snapshotImpl 不会占用过多的内存,而且也保证了固化块能够被及时的持久化存储下来。
数据库原子性¶
java-tron 的数据库存储与其他公链略有区别,例如以太坊持久化层只采用了一个数据库实例,以太坊中的不同类型的数据用前缀加以区分,存储在一个数据库实例中。而 java-tron 目前则将不同业务类型的数据存放在各自的数据库实例中。
两者实现方式各有千秋,单实例方便维护,能够统一写入,但缺点也较明显,比如随着时间推移单库数据量不断增长,某些业务数据库的频繁访问可能会拖累其他业务的读写性能。
多实例则不存在各个业务数据读写相互影响的问题,且可以根据各自的数据量与性能要求配置不同的参数,达到性能最大化,还可以将数据量较大的库独立拆分出去,以缓解数据膨胀问题。但多数据库实例存在一个严重的问题:并没有原生工具支持多数据库实例之间的原子写入。
java-tron 为了保证数据库多实例的原子写入,新增了 checkpoint 机制,在多实例落盘前将变更的数据统一写入 checkpoint,若多个数据库实例在写入时发生意外,服务重启时从 checkpoint 中将变更的数据统一恢复,保证写入的原子性。
上一节中固化块的 snapshotImpl 写入数据库的过程主要包含了两步:
- 创建 checkpoint
- snapshotImpl 执行落盘操作
创建 checkpoint 这个操作比较关键, checkpoint 是将内存中需要写入数据库的 snapshotImpl 先持久化的存储在一个 tmp 的数据库中(目前底层实现的是leveldb、rocksdb),创建 checkpoint 成功之后才会进行 snapshotimpl 的落盘操作,假如此时落盘时机器宕机,那么节点再次启动时,会首先搜索是否存在 tmp 的 checkpoint 数据,如果存在的话,会将 checkpoint 中的数据回放至 snapshotRoot 中。
Checkpoint 数据结构如下:
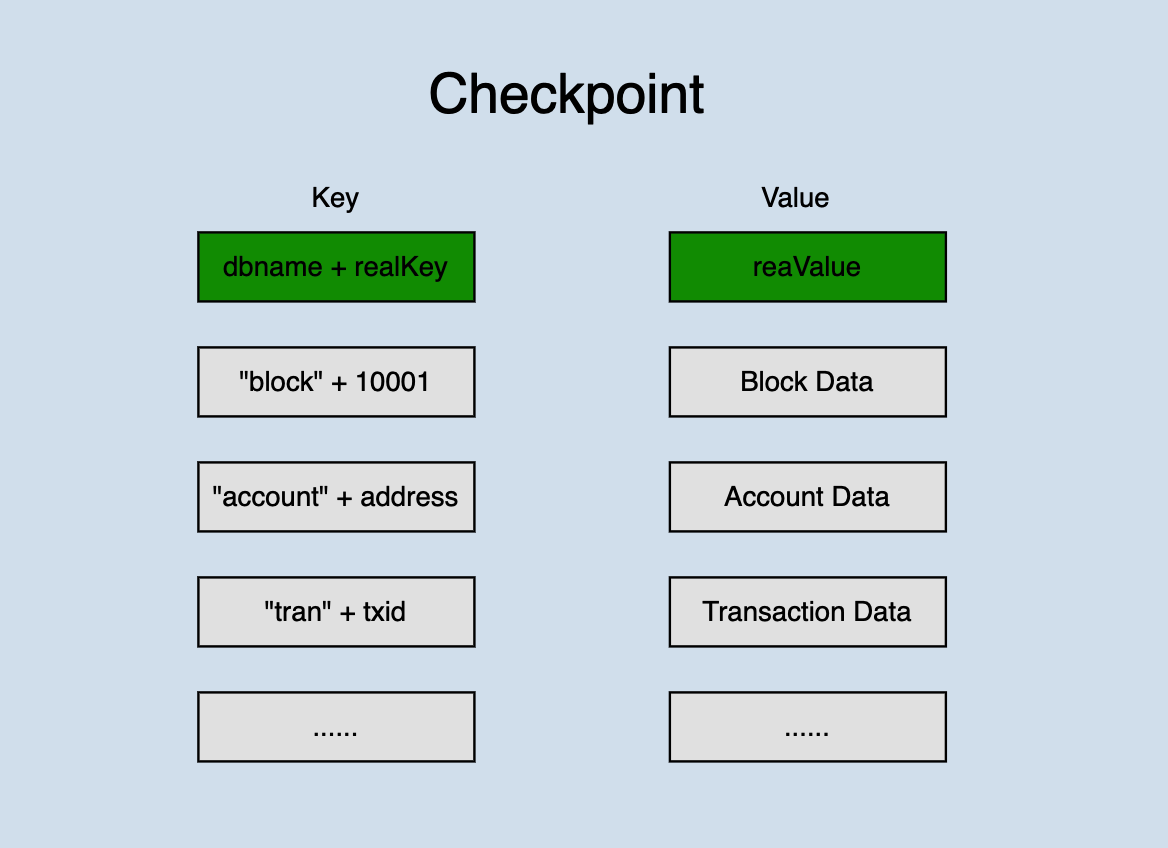
checkpoint将一次状态变更的所有数据统一存放在一个数据库中,不同类型的数据采用前缀加以区分,并且为了保证本次所有的变更数据能够全部落盘,写入时采用数据库底层调用writeBatch() 的方式。
这种解决的思路可以总结为:
- 多数据库实例之间无法保证写入的原子性,但单数据库(大部分主流数据库)支持原子性写入
- 将需要保证原子性写入的数据集首先采用原子写入的方式,写入到一个临时库,然后将数据分别写入不同的数据库实例,如果发生意外,通过临时库的数据来恢复即可。
总结¶
本文通过交易和区块的处理流程来分析了 chainbase 模块中回滚和数据库写入的实现细节,还分析了数据库多实例的原子写入的原理,防止意外宕机导致数据库损坏,希望通过阅读本文能有助于开发者进一步了解和开发java-tron数据库。