ChainBase Deep Dive¶
Introduction¶
As we all know, the blockchain is essentially a non-tamperable distributed ledger, which is very suitable for solving the problem of trust. Blockchains are frequently used for secure bookkeeping and transaction processing. For example, applications utilize cryptocurrencies like BTC, ETH, and TRX to conduct economic activities while ensuring financial transparency.
The realization of such an immutable distributed ledger is a very complex system engineering, involving many technical fields: such as p2p networks, smart contracts, databases, cryptography, consensus mechanisms, etc. Among them, the database is the basis of the underlying storage, and various blockchain teams are exploring the design and optimization of the database level.
The Database module of java-tron is also called the ChainBase module. This article mainly introduces some background knowledge and shows developers the implementation details of the ChainBase module by introducing logic such as transaction processing, state rollback, and data persistence.
Prerequisites¶
The database is an important part of the blockchain system. It stores all the data on the blockchain and is the basis for the normal operation of the blockchain system. Each fullnode stores a full amount of data, including block data, state data, etc. java-tron uses the Account model to save the user's account state.
Account Models¶
There are currently two mainstream account models,
- UTXO
- Account Model
The UTXO model is stateless, makes it easier to process transactions concurrently, and has better privacy, but it is not programming-friendly.
In the Account Model, user data is stored in the corresponding account, and smart contracts are also stored in the account in the form of code. This model is more intuitive and easier for developers to understand. For programmability, flexibility, and other considerations, java-tron adopts the Account Model.
Consensus¶
The current mainstream consensus is PoW, PoS, DPoS, etc. PoW is proof of work, all nodes participate in the calculation of an expected hash result, and the node that first calculates the result has the right to produce a block, but as the computing power continues to increase, the energy consumption required to calculate the hash is also increasing. Moreover, large mining farms monopolize most of the computing power, which also goes against the original intention of decentralization.
To solve the problems faced by PoW, some people proposed PoS (Proof of Stake), which is simply understood as the more coins that the node holds, the greater the probability of obtaining the right to produce blocks, but this will lead to monopoly problems as well. In order to improve, DPoS (Delegated Proof of Stake) is proposed: the decentralization feature is guaranteed by the elected super representative, and the super representative is responsible for the block production in turn to improve the efficiency. java-tron currently adopts the DPoS consensus mechanism.
To learn more, please refer to Delegated Proof of Stake.
Persistent Storage¶
There are certain differences between blockchain and traditional Internet business. The blockchain does not have particularly complex processing logic at the database level, but there are a large number of key-value read and write operations in the blockchain so there are higher requirements for data read and write performance.
Based on this consideration, java-tron uses LevelDB as the underlying data storage by default (on ARM64 architecture, RocksDB is forced regardless of the configuration, since LevelDB is deprecated on ARM), and java-tron has a good architecture design. The interface-oriented programming mode makes the Chainbase module have better scalability. All databases implemented the chainbase interface can be used as the underlying storage engine of java-tron. For example, in the chainbase v2 version, a database implementation based on RocksDB is provided.
Transaction Validation¶
As we all know, the blockchain mainly stores transaction data. Before introducing the Chainbase module, you need to understand the transaction processing logic in java-tron.
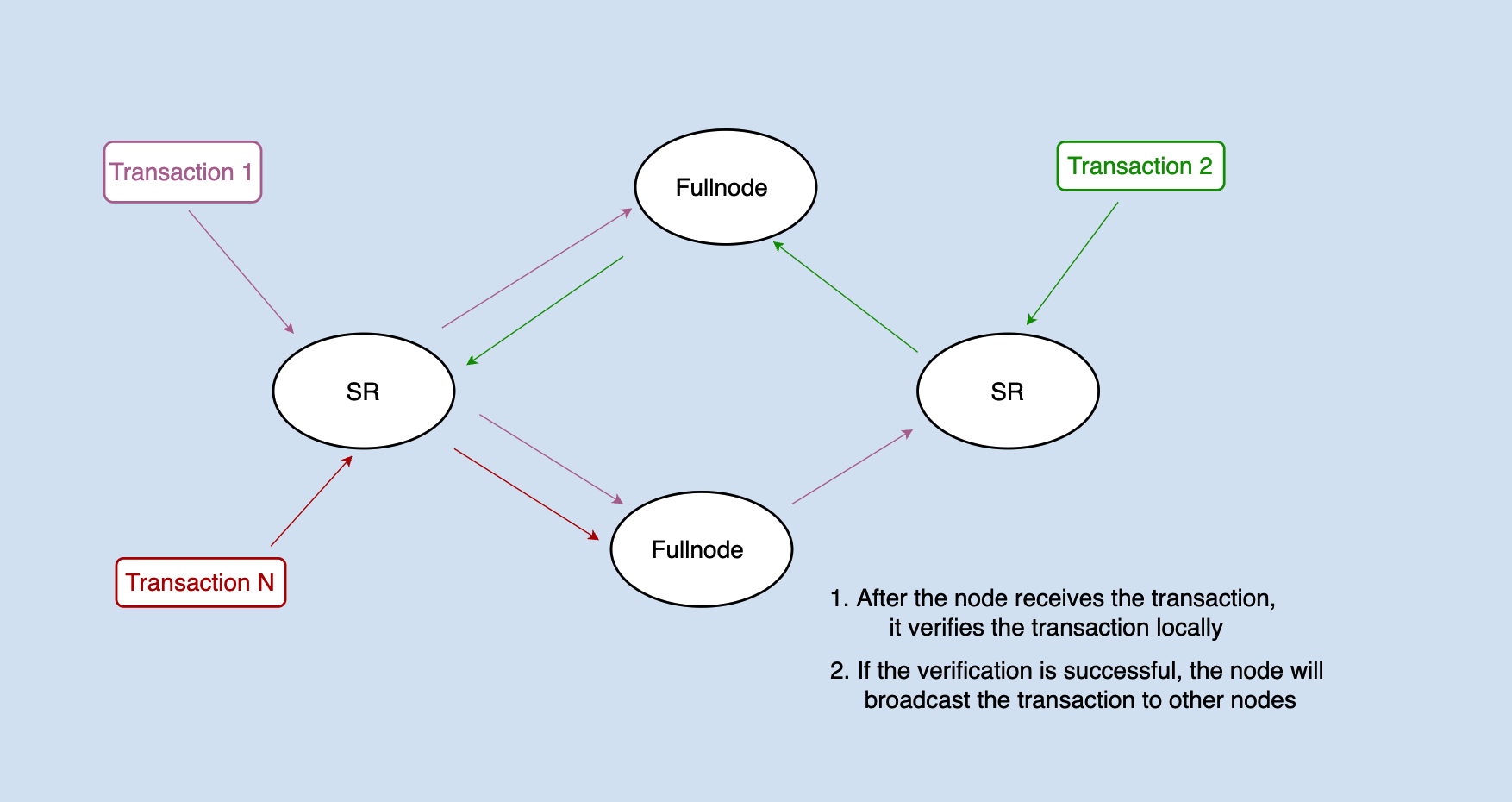
The transaction will be distributed to each node through network broadcast. After receiving the transaction, the node will first validate the signature of the transaction. If successful, the transaction needs to be pre-executed to determine whether the transaction is legal.
Note: The specific implementation in java-tron may deviate slightly from the simplified figure above. For convenience, this article collectively refers to FullNodes and Super Representatives (SRs) simply as 'nodes'.
For example, to process a transfer transaction: user A transfers 100 TRX to user B, and it needs to validate whether user A has enough balance to make the transfer.
The account library in the database stores the account information of all users, including the user's balance information. How to judge whether this transfer transaction is legal? The logic of java-tron is: when a transaction is received from the network, the transaction operation will be executed immediately, that is, the account information will be modified in the local database: (accountA - 100TRX, accountB + 100TRX). If this operation can be executed successfully, it means that the transaction is legal at least in the current state, and can be packed into the block.
Glossary¶
SR: Super Representative, is responsible for block production.
FullNode: stores all block data, is responsible for transactions, block broadcasting and validation, and provides query services.
TRX: TRON native token.
State Rollback¶
Above we mentioned that java-tron validates whether the transaction is legal through pre-execution, but what we need to know is that the transaction is successfully validated on a certain node does not mean that the transaction has been successfully chained because the transaction has not been packed into the consensus blocks, there is a risk of being rolled back.
The consensus of java-tron follows a principle: that is, the transactions in the blocks that are approved by more than 2/3 of the SRs are the ones that are really successful on the chain. can also be understood as below,
- transactions are packed into a block
- the block is approved by more than 2/3 of the SRs
A transaction that satisfies the above two points is a successful transaction on the chain. A transaction in java-tron is finally confirmed through three stages,
- transaction validating
- transaction packing into the block
- block being accepted, applied, and eventually solidified
This also leads to a problem: in the implementation of java-tron, if a node validates the transaction, its database state changes accordingly. If the transaction is not packed into the block yet or the block it is packed into has not been approved by more than 2/3 of SR, the state of this node will be inconsistent with the state of the entire network.
Therefore, except for the processing transaction data in blocks approved by more than 2/3 SRs, all other data state changes resulting from transaction processing may need to be rolled back. There are three kinds of scenarios in total:
- after receiving a new block, roll back the state changes generated by transaction validation
- after producing a block, roll back the state changes generated by transaction validation
- if a forked takes place, roll back the state changes generated by the transactions of the blocks in the forked chain
The data state changes caused by these three scenarios may need to be rolled back and the following section explains why.
Rollback after Receiving a New Block¶
When receiving a new block, the node needs to roll back to the state at the end of the previous block and roll back all transactions validated afterward. As shown below,
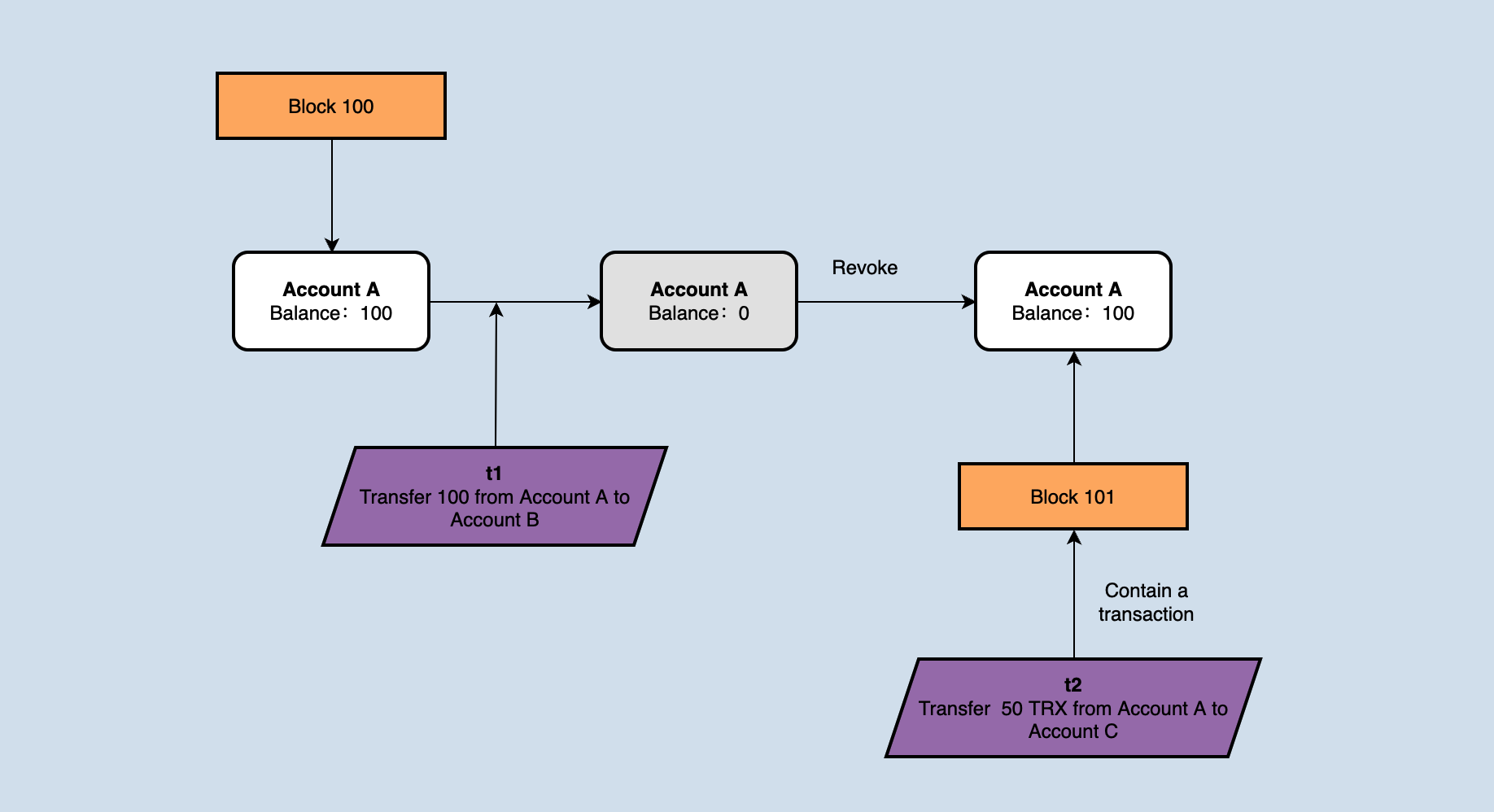
If the account balance of accountA is 100 at the block height is 1000, the node receives and validates a transaction 't1', in which accountA transfers 100TRX to accountB. After receiving the new block1001, the block contains a transaction 't2', in which accountA transfers 50TRX to accountC. In theory, t2 has been packed into the block, and the priority is higher than t1. However, if no operation is done, the validation of t2 will fail because accountA does not have enough balance. Therefore, after receiving the new block 1001, the state change generated by transaction t1 needs to be rolled back.
Rollback after Producing a New Block¶
First of all, readers may have a question: the validated transaction can be directly packed into the block, and it will not change the database state. Why is there a change in the database state?
Because java-tron does a secondary validation of the transaction when it is packed into the block. The secondary validation is due to the timeliness of the transaction. Still taking the above figure as an example, it can be seen from the figure, that after 1001 is received, the transaction t1 was rolled back, and the balance of accountA was deducted by 50. And then, it was the node's turn to produce a block, but t1 had become an illegal transaction at this time because the balance in accountA was not enough to transfer 100 TRX, it is not advisable to directly pack t1 into the block. So the transaction needs to be validated again, which is why the transaction needs to be validated twice when producing a block.
After the block is packed successfully, the node will broadcast the block to the network and apply the block locally. And the logic of applying will re-check the transactions in the block. So after the block is packed, a rollback operation still needs to be performed.
Rollback when Forking¶
This is the last rollback situation, and the blockchain will inevitably fork, especially the blockchain system based on DPoS with a faster block production speed that is more prone to fork.
java-tron maintains a data structure in memory as below,
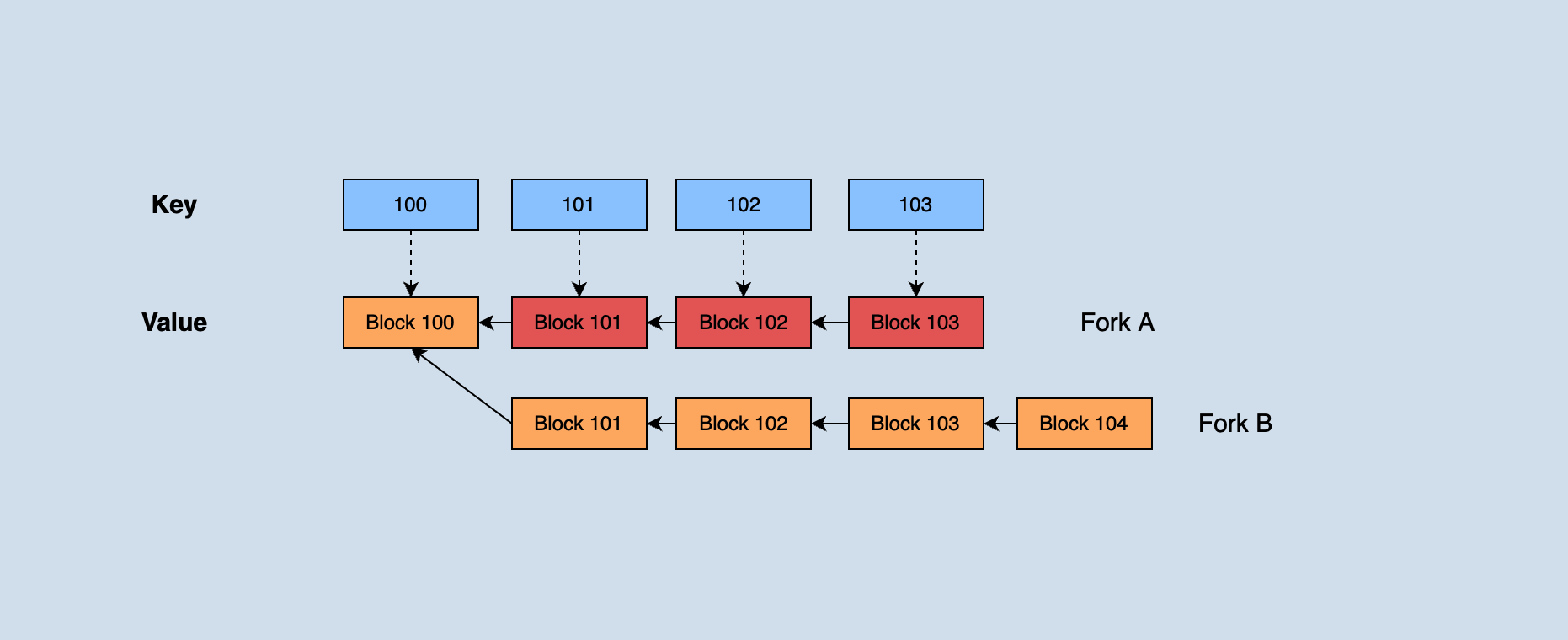
java-tron holds all blocks that have not reached consensus recently. When a forked chain occurs, according to the longest chain principle: if the block height of the forked chain is greater than the current main chain block height, the forked chain needs to be switched to the main chain. Part of the blocks on the previous main chain needs to roll back up to their common parent blocks when switching, and then apply new main chain blocks sequentially from the parent block.
As shown in the figure, fork A in the dark part was originally the main chain. Because the height of fork B continues to grow and eventually exceeds the height of A, it is necessary to roll back the data in those three blocks with heights 1003, 1002, and 1001 in fork A. Then apply fork blocks 1001', 1002', 1003', and 1004' in B in sequence.
State Rollback Implementation¶
This chapter explains receiving and validating transactions, block production, validating and saving blocks from the perspective of code, to further analyze the chainbase module of java-tron. If there is no further declaration, the default description is dedicated to all the Fullnode (including SR).
Receiving Transactions¶
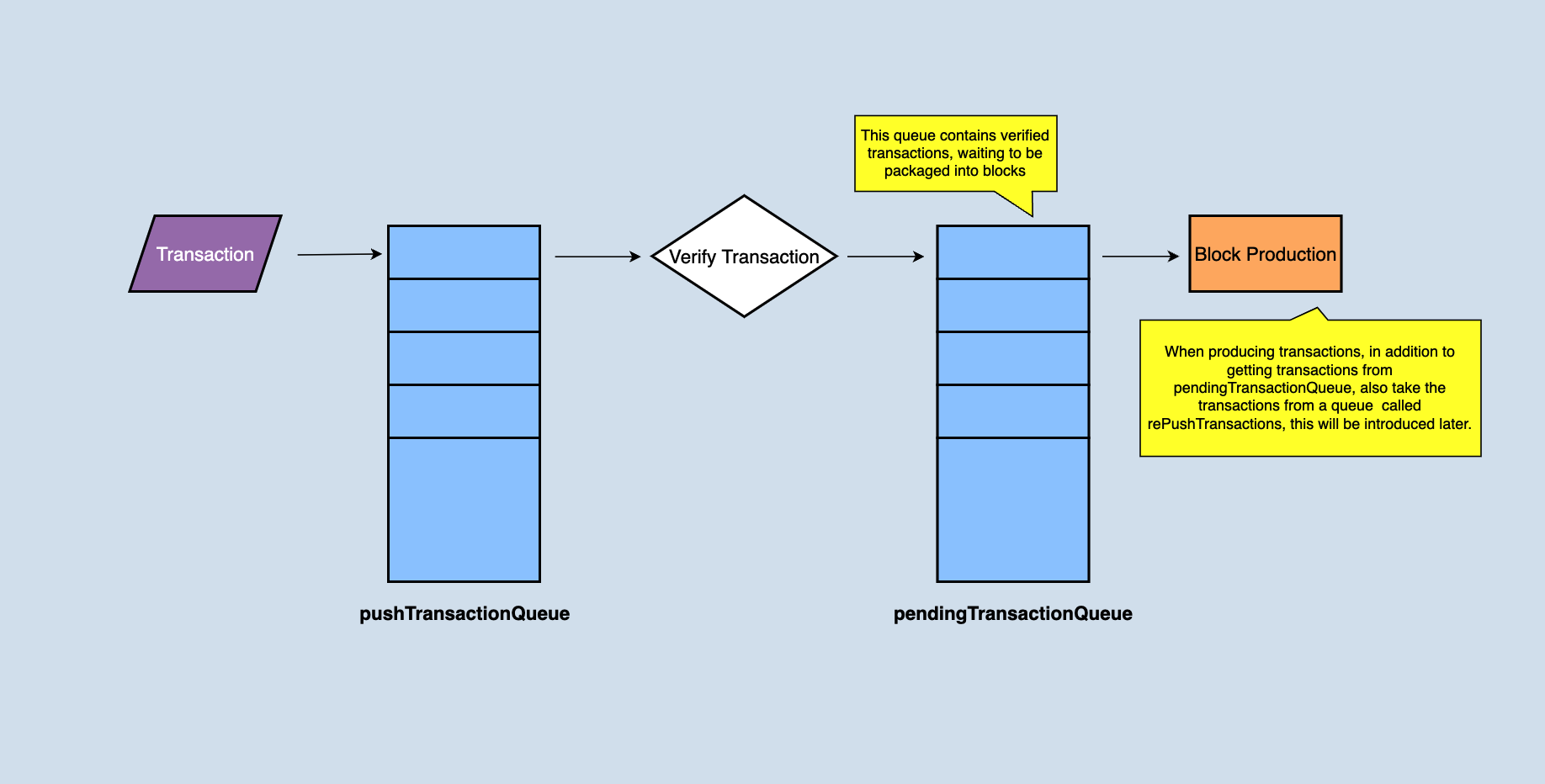
After the node receives a transaction, it puts the transaction into the local pushTransactionQueue cache queue by calling the pushTransaction(final TransactionCapsule trx) function of the manager class and validates the transaction at the same time. And the return of this method is sort of elegant:
- if validation is successful, ‘true' is returned
- for the transaction sent by the user to the node through the API, if the transaction validation fails, an exception will be returned to the user; for transactions received from other nodes through the network, exceptions will only be recorded locally
After the transaction validation is successful, the transactions without problems will be put into the pendingTransactionQueue, and the pendingTransactionQueue is responsible for providing the transaction set when producing blocks. If the node is an SR node, when producing a block, it will take out all or part of it from the pendingTransactionQueue (depending on how many transactions are in the pendingTransactionQueue) to generate a block.
Rollback when Receiving Blocks¶
A node would receive transactions broadcasted from other nodes before receiving a new block, the transactions need to be validated to determine whether they can be executed correctly. Validation means that the state needs to be changed, and a successful validation does not mean that the transaction will be finally executed, and it will be considered successful after packing into a block and the block become solidified. This step can be considered to filter out those obviously wrong transactions in advance. This is just validation. When a new block arrives, the state changed by transaction validations should be rolled back. The state produced by applying new blocks will not be rolled back during this pending-transaction cleanup step; however, before a block is solidified, its applied state may still be rolled back when a fork switch occurs.
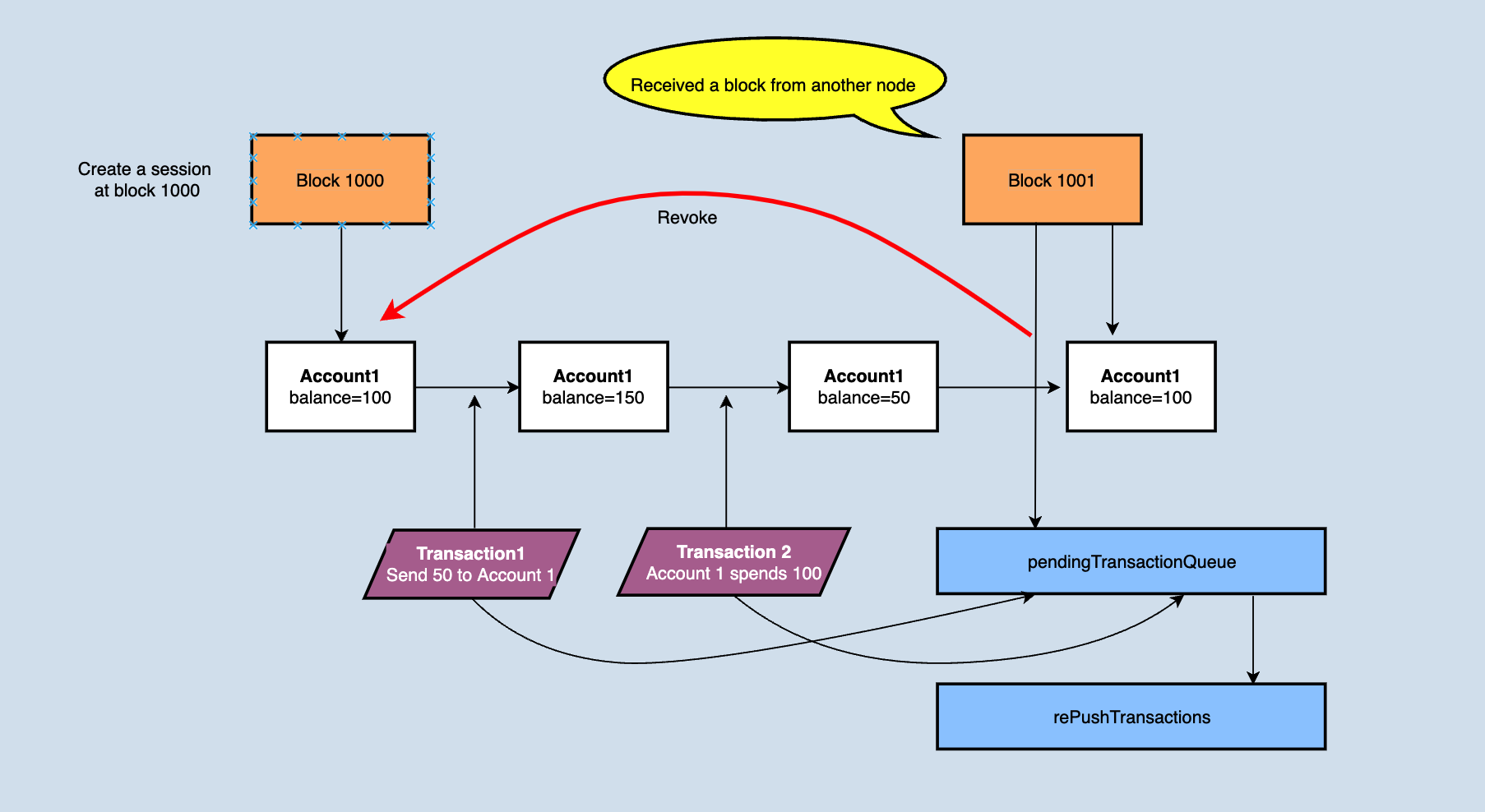
When rolling back, java-tron move the transactions in the pendingTransactionQueue to rePushTransactions, and clear the pendingTransactionQueue, see the figure for a detailed explanation.
Why does the pendingTransactionQueue need to be emptied after a new block arrives? First of all, it is clear that the pendingTransactionQueue queue is responsible for providing transaction data when generating blocks, that is to say, it stores validated transactions that can be directly packed into blocks. Since the new block will also change the account state, those validated transactions in pendingTransactionQueue may not pass the validation after applying the new block (the simplest example: a transaction in the new block is that accountA spends a part of the token, resulting in a transaction amount of accountA in the queue that is not enough to pay ). After the transaction is moved to rePushTransactions, a background thread will be responsible for re-validating the transaction in the queue. If nothing is wrong, it will be put into the pendingTransactionQueue again to provide data for block production.
There is a session object in java-tron. A session represents the change in the state of a block. The session object is mainly used for rollback. For example,rolling back the state to the state of the previous block needs to be operated throughout the session, as shown in the following figure,
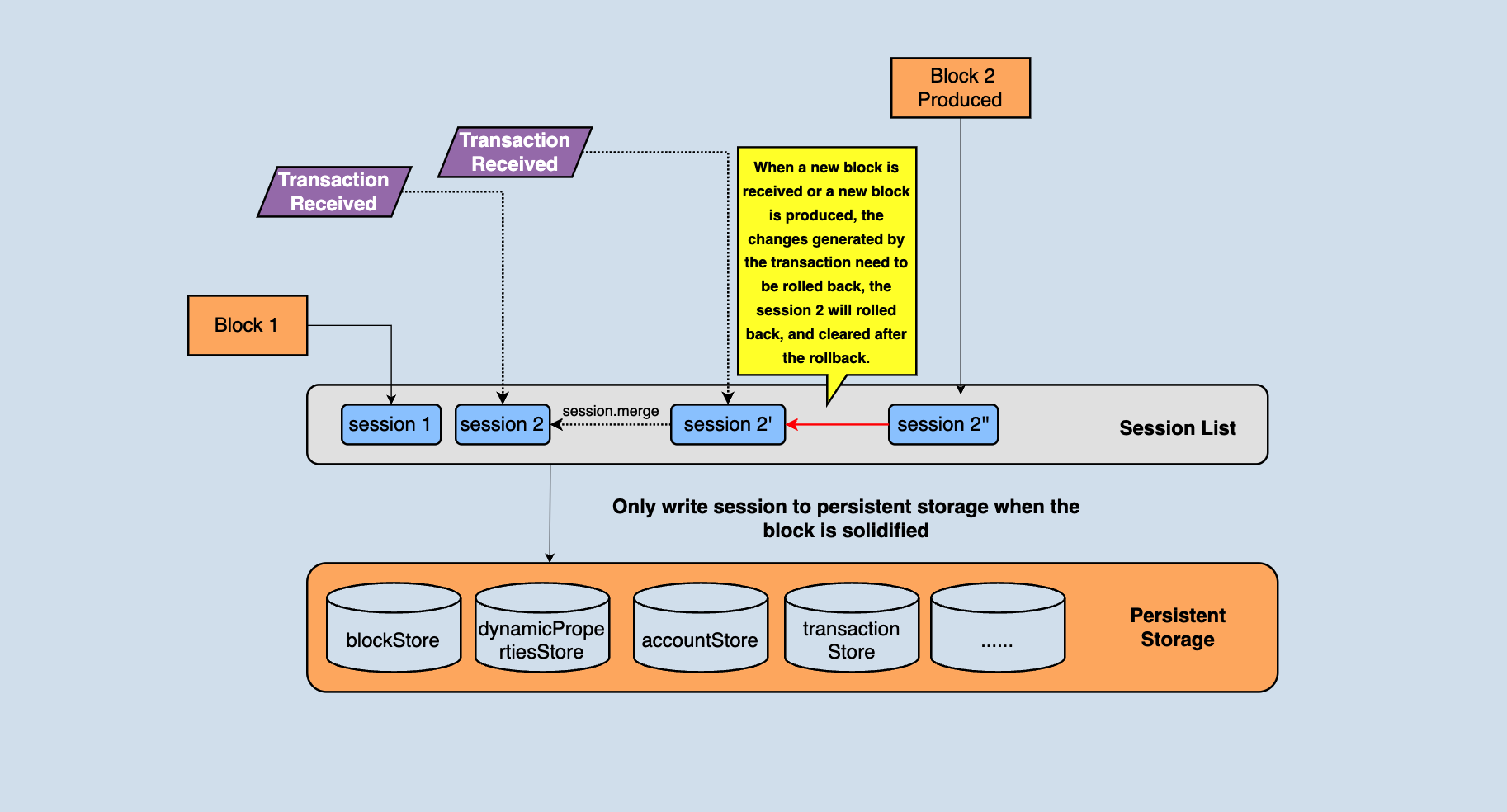
In the above figure, you can see that there are many different types of databases in persistent storage. These data are jointly organized into a complete blockchain. For example, blocks are stored in khasodb and blockStore, and account information is stored in accountStore...
The node maintains a session chain table, which stores the change information corresponding to the block/transaction, and the node can roll back through the change information. In the above figure, session1 is the status change of the current highest block. When a transaction is received, a new session2 will be generated. Each transaction that comes later will generate a temporary tmpSession, and after the transaction is validated, the tmpSession corresponded will be merged to session2. Before a new block is received again, all status changes generated by transaction validation will be saved in session2. When a new block arrives, directly execute the reset method of the session2 to roll back the state to the previous block.
Rollback when Producing Blocks¶
SR needs to roll back before producing blocks. The reasons are more complicated. Let's consider a scenario first:
- The pendingTransactionQueue stores the currently validated transactions, so when an SR node produces a block, it only needs to directly pack the transactions in the pendingTransactionQueue into the block, and then roll back the state to the state of the previous block after packing.
However, there is a problem with this scheme: if the SR node has just received and applied a new block, the pendingTransactionQueue will be cleared. At this time, it is the turn of the SR to pack the block, but there is no transaction in pendingTransactionQueue. Therefore, the real implementation is that not only reads transactions from pendingTransactionQueue when generating blocks but also reads transactions from rePushTransactions and puts them into blocks if there are few transactions in pendingTransactionQueue. The above analysis shows that transactions in rePushTransactions may not be possible to pass the validation, so the transactions need to be validated again. Due to this validation logic, the state needs to be rolled back before the block is produced.
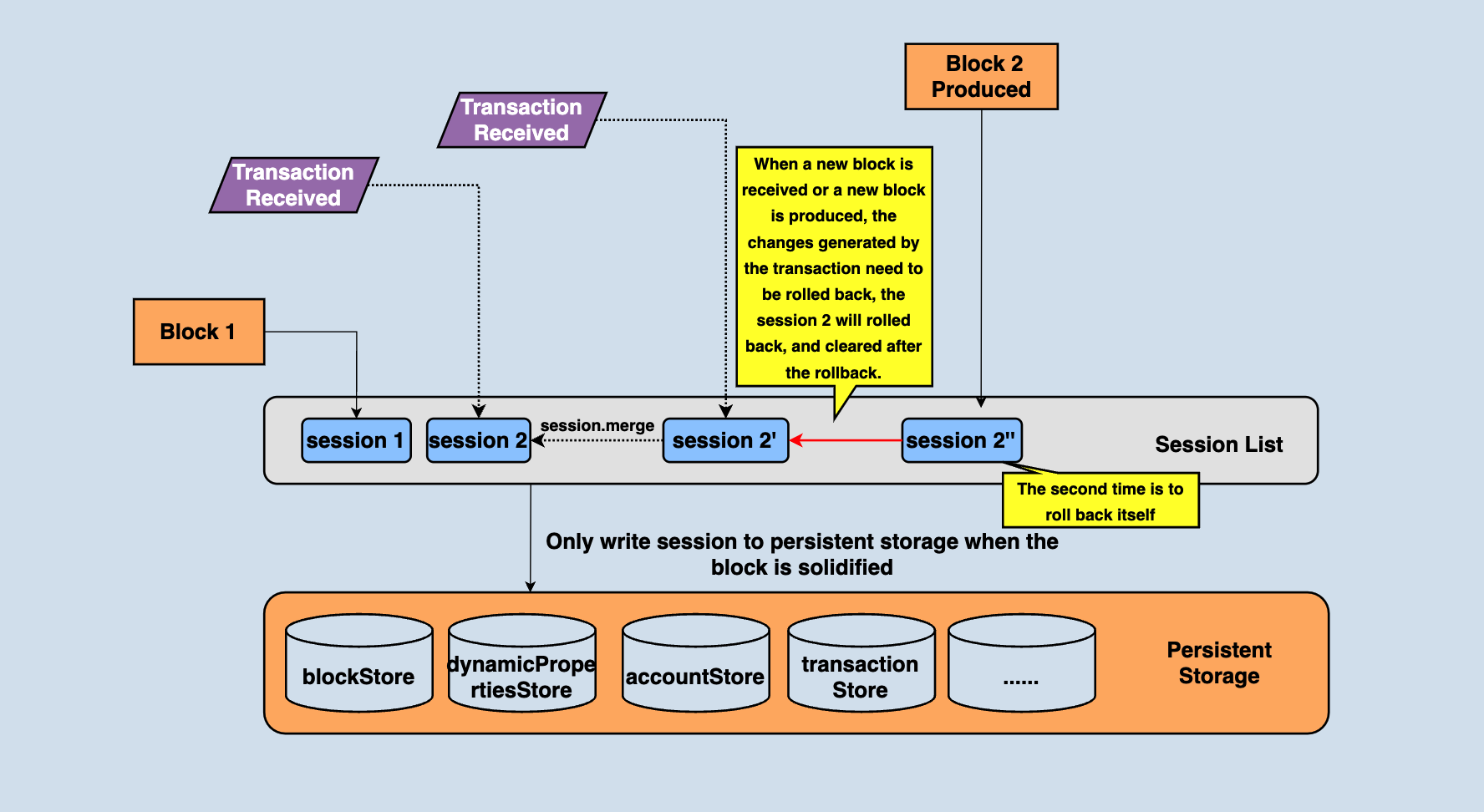
In the process of producing the block, the transaction will be validated again, so there will be a state change, but this is just block production, and the block needs to be broadcast as well, and those blocks who received the broadcast will actually change the state, so the state changes incurred by block production also need to be rolled back. As shown in the figure above, when the block production is completed, session2" needs to be rolled back.
Block Solidity¶
java-tron adopts the DPoS consensus mechanism. The DPoS of java-tron is to vote for 27 nodes as block producers (also known as SR), SR has the right and obligation to produce blocks, and blocks approved by more than 2/3 of SR are considered to reach a consensus. These blocks, which are no longer rolled back are called solidified blocks. The state of non-solidified blocks is first written into rollbackable in-memory snapshot layers (sessions); only solidified snapshot layers are flushed and merged into the persistent storage.
SnapshotManager in java-tron is the key entry to the storage module, holds references to all current business databases, and stores database references in a list. Each database instance supports adding a new layer of state set on its own called SnapshotImpl. It is an in-memory hashmap, multiple SnapshotImpl are associated in the form of a linked list, and one SnapshotImpl retains the data modification (in-merging or merging) involved in one state change, and SnapshotImpl is independent of each other. They are separated through this data structure, as shown in the following figure,
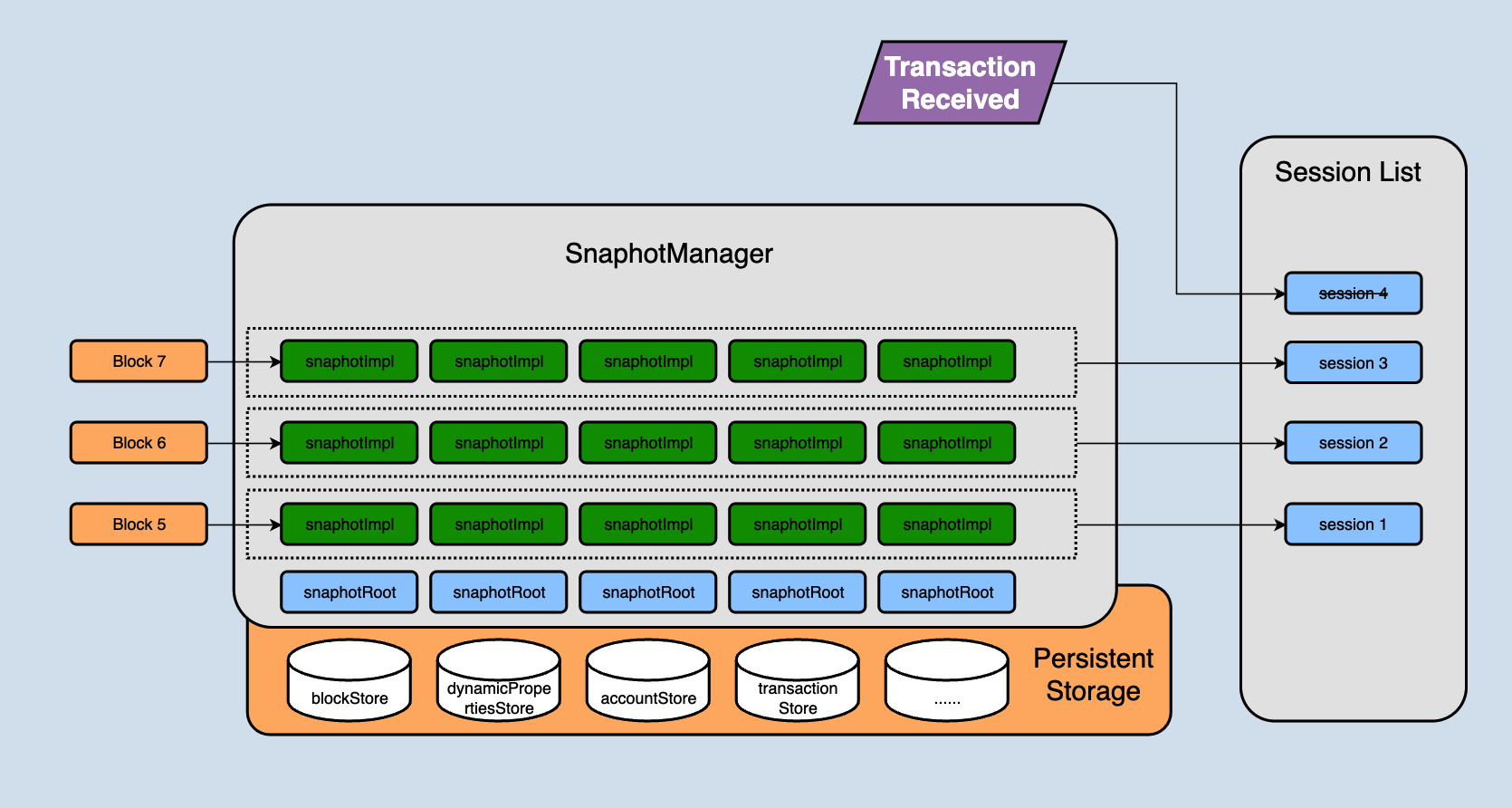
The SnapshotRoot in the above figure is the encapsulation class for the persistent database, which is responsible for storing the solidified data.
In the previous chapters, we talked about sessions. A session represents the changes of state in a block. In fact, a session contains the SnapshotImpl corresponding to each database. For example, all SnapshotImpl in the layer of block 5 in the above figure together constitutes the changes of block 5 to the entire database.
The changes generated after the node receives a new block will not be directly stored in the persistent storage (SnapshotRoot), but will first be stored in snapshotImpl. Each block received corresponds to a snapshotImpl. Continuously receiving blocks will lead to more and more snapshotImpl. When will they be written to persistent storage?
There are two variables in SnapshotManager: 'size' and 'maxSize'. Here we simply understand 'size' as how many layers of snapshotImpl are there currently in memory, and 'maxSize' represents the difference between the height of the current solidified block and the latest block.
This is obvious. If 'size' > 'maxSize', it means that the blocks corresponding to the first (size-maxSize) snapshotImpl are already solidified blocks, they can be placed on the disk, and then the snapshotImpl will be merged into the persistent storage. This ensures that snapshotImpl does not occupy too much memory, and also ensures that the solidified block can be persisted in time.
Atomicity¶
The database storage of java-tron is slightly different from other public chains. For example, the Ethereum persistence layer uses only one database instance, and different types of data in Ethereum are distinguished by prefixes and stored in one database instance. However, java-tron currently stores data of different business types in its own database instances.
The two implementations have their own advantages. A single instance is easy to maintain and can be written uniformly, but the disadvantages are also obvious. For example, the amount of data in a single database continues to grow over time, and frequent access to some business databases may drag down the read-and-write performance of other businesses.
Multi-instance does not have the problem of the mutual influence of each business data read and write, and can configure different parameters according to their respective data volume and performance requirements to maximize performance, and can also independently split the database with a large amount of data. Alleviate data bloat problems. But there is a serious problem with multiple database instances: there is no native tool to support atomic writes among multiple database instances.
In order to ensure the atomic writing of multiple database instances, java-tron has added a checkpoint mechanism, which writes the changed data to the checkpoint uniformly before the multiple instances are placed on the disk. If an accident occurs in writing to multiple database instances, the changed data will be recovered from the checkpoint when the service is restarted to ensure the atomicity of writing.
The process of writing the snapshotImpl of the solidified block to the database in the previous section mainly includes two steps,
- create a checkpoint
- place snapshotImpl on disk
The operation of creating a checkpoint is more critical. A checkpoint is to persistently store the snapshotImpl in memory that needs to be written to the database in a tmp database (currently, the underlying implementation is leveldb and rocksdb). After the checkpoint is successfully created, the snapshotImpl will place on the disk. If the machine is down while placing, it will first search for the existence of tmp checkpoint data when the node restart. And if so, the data in the checkpoint will be played back to snapshotRoot.
A checkpoint data structure,
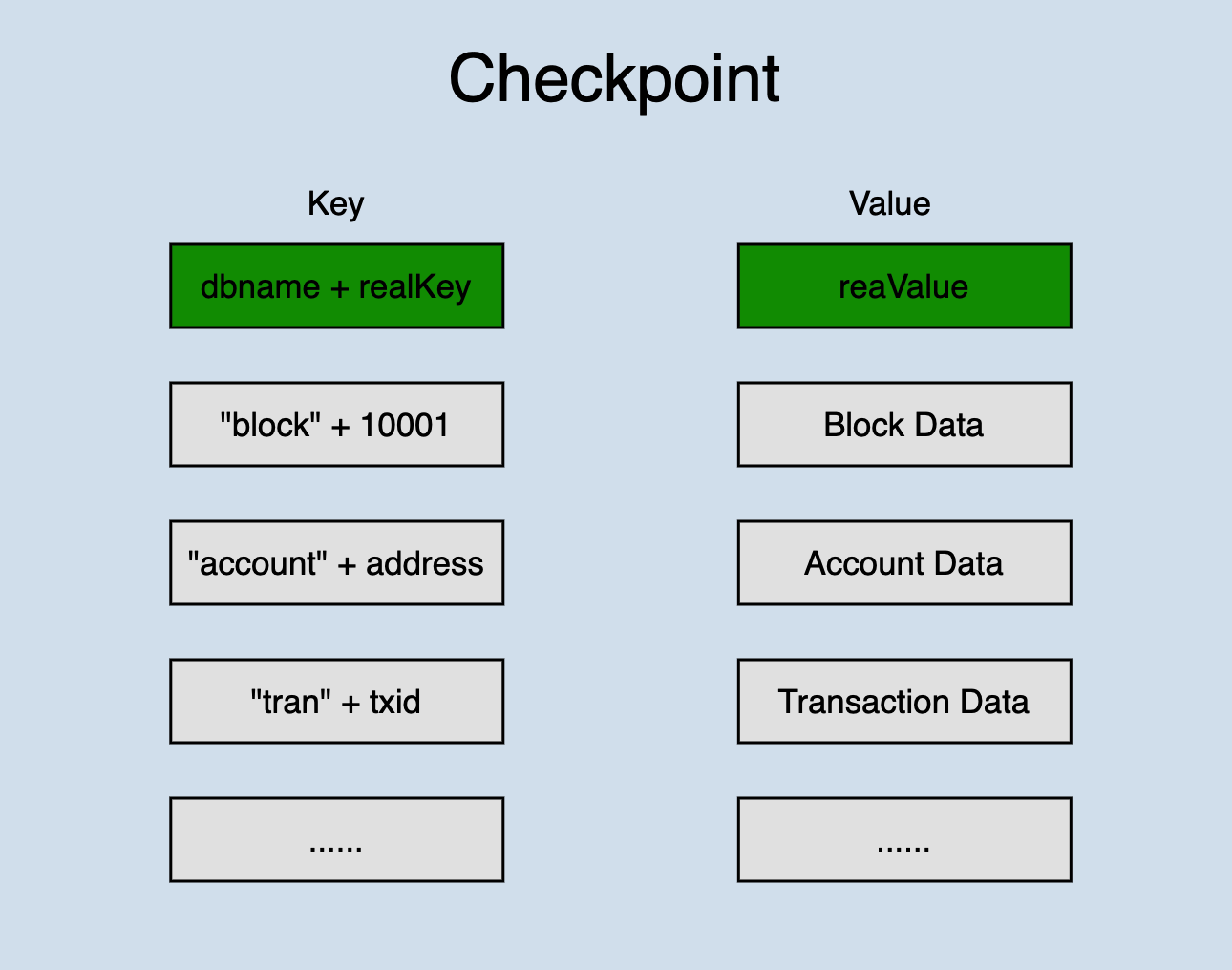
Checkpoint stores all data of a state change in one database. Different types of data are distinguished by prefixes. In order to ensure that all changed data can be placed on disk this time, the bottom layer of the database calls writeBatch() when writing.
This solution can be summarized as,
- the atomicity of writes cannot be guaranteed among multiple database instances, but a single database (most mainstream databases) supports atomic writes
- the data set that needs to be guaranteed to be written atomically is first written to a temporary database by atomic writing, and then the data is written to different database instances; if an accident occurs, it can be recovered through the data of the temporary database
Summary¶
This article analyzes the implementation details of rollback and database writing in the chainbase module through the processing flow of transactions and blocks and also analyzes the principle of atomic writing among multiple instances of the database to prevent database damage caused by accidental downtime. We hope that reading this article can help developers to further understand and develop the java-tron database.