P2P Network Deep Dive¶
This article focuses on how the P2P network works internally (architecture, block synchronization, and broadcast). For how to configure a node to discover peers and connect to a network (config.conf parameters, boot/seed nodes, active/passive peers), see Connect to the TRON Network.
Overview¶
A Peer-to-Peer (P2P) network is a distributed architecture where participants share a portion of their hardware resources, such as processing power, storage capacity, network connection capacity, printers, etc. These shared resources need to be provided services and content by the network, which can be accessed by other peers directly without going through an intermediate entity. Participants in this network are both providers and acquirers of service and content.
Unlike traditional Client/Server architectures, all nodes in a P2P network have equal status. While serving as a client, each node can also serve as a server to provide services to other nodes, which greatly improves the utilization of resources.
Blockchain Network¶
P2P is the network layer in the blockchain structure. The main purpose of the network layer is to realize information broadcast, verification and communication between nodes. The blockchain network is essentially a P2P network, and each node can both receive and generate information. Nodes keep communication by maintaining common blockchain data.
As the foundation of the blockchain, the P2P network brings the following advantages to the blockchain:
- Prevent single-point attack
- High fault tolerance
- Better compatibility and scalability
TRON Network¶
The architecture diagram of TRON is as follows:
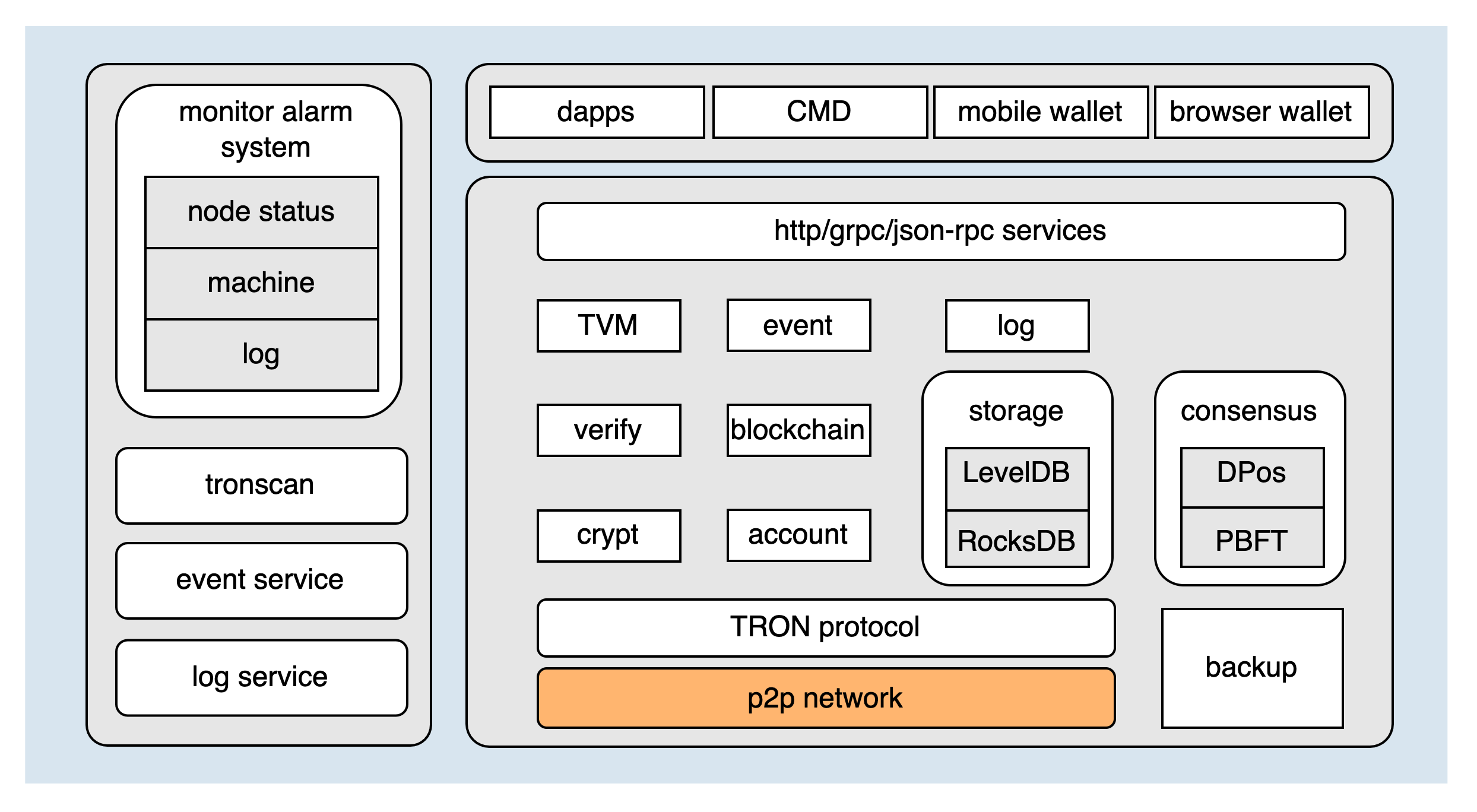
As the most fundamental module of TRON, the P2P network directly determines the stability of the entire blockchain network. The network module can be divided into the following four parts according to the function:
- Node Discovery
- Node Connection
- Block Synchronization
- Block and Transaction Broadcast
The underlying implementations of Node Discovery and Node Connection have been extracted from the java-tron repository into a standalone external dependency, io.github.tronprotocol:libp2p. This library is responsible for low-level node discovery (based on the Kademlia algorithm) and connection transport, and it adds capabilities such as DNS-based node discovery. The TRON protocol layer above it — including the P2P_HELLO handshake, P2P_PING/P2P_PONG keep-alive, peer business-state management, message dispatch, synchronization, and broadcast — is still implemented in java-tron's core/net, which integrates with libp2p through TronNetService. For the low-level discovery and connection implementation details, please refer to the libp2p repository; they are no longer covered in this document.
Block Synchronization and Block and Transaction Broadcast are still implemented in java-tron's core/net, and are introduced separately below.
Block Synchronization¶
After completing the handshake with the peer node, if the peer node's blockchain is longer than the local blockchain, the block synchronization process syncService.startSync will be triggered according to the longest chain principle. The message interaction during the synchronization process is as follows:
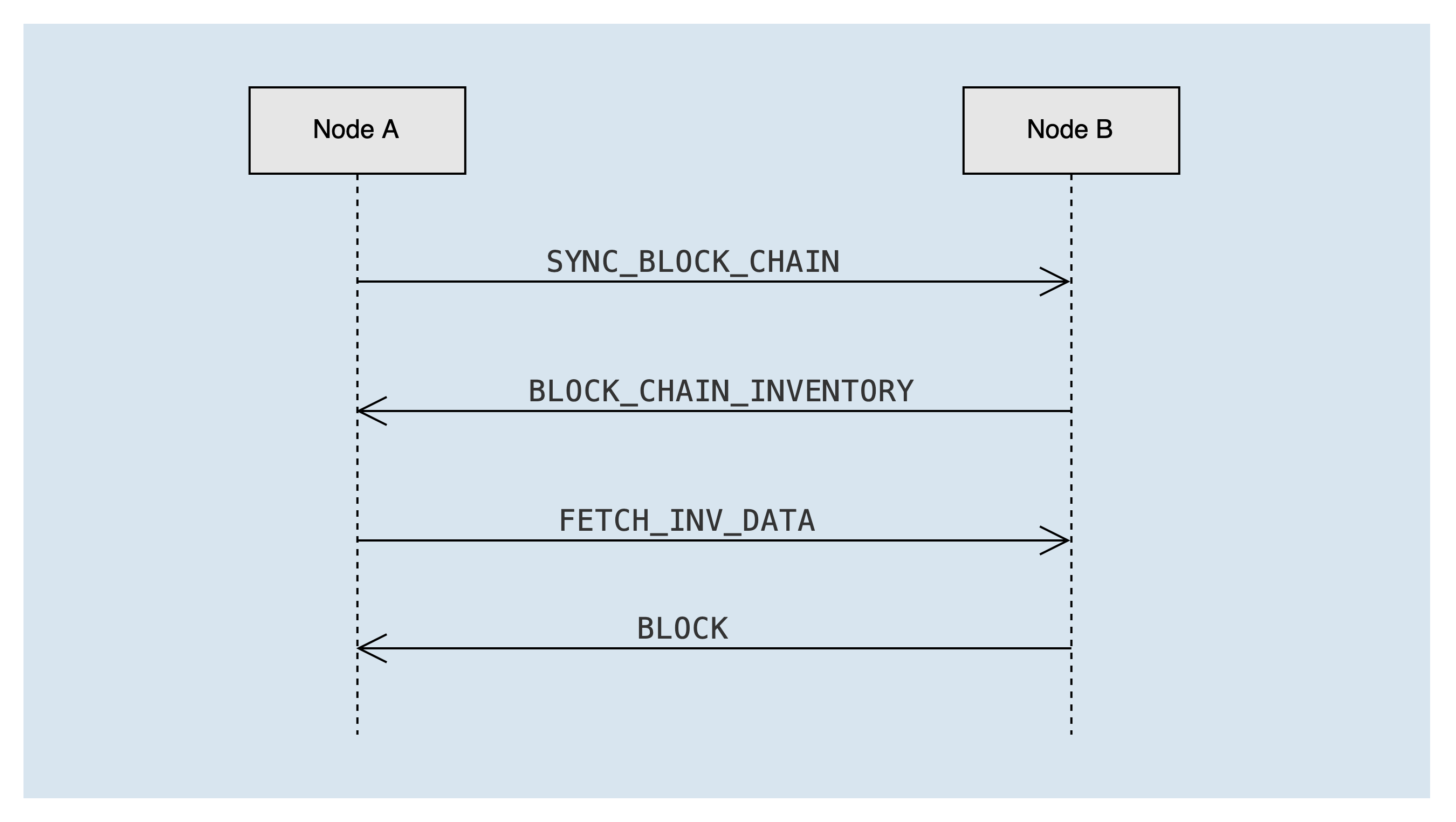
Node A sends an SYNC_BLOCK_CHAIN message to peer node B to announce the blockchain summary information of the local chain. After the peer node B receives it, it calculates the list of missing blocks of node A, and sends the lost block ID list to node A through the BLOCK_CHAIN_INVENTORY message, carrying a maximum of 2000 block ids at a time.
After node A receives the BLOCK_CHAIN_INVENTORY message, it gets the missing block id, and sends a FETCH_INV_DATA message to node B asynchronously to request the missing block, up to 100 blocks at a time. If there are still blocks that need to be synchronized (that is, the remain_num in the BLOCK_CHAIN_INVENTORY message is greater than 0), a new round of block synchronization process will be triggered.
After node B receives the FETCH_INV_DATA message from node A, it sends the block to node A through the BLOCK message. After node A receives the BLOCK message, it asynchronously processes the block.
Blockchain Summary and List of Missing Blocks¶
Below will take several different block synchronization scenarios as examples to illustrate the generation of the blockchain summary and the lost block ID list.
- Blockchain summary: an ordered list of block IDs, including the highest solidified block, the highest non-solidified block, and the blocks corresponding to the dichotomy.
- List of missing blocks: The neighbor node compares its own chain with the received blockchain summary, determines the missing blocks list of peers, and returns a set of consecutive block IDs and the number of remaining blocks.
Normal Synchronization Scene¶
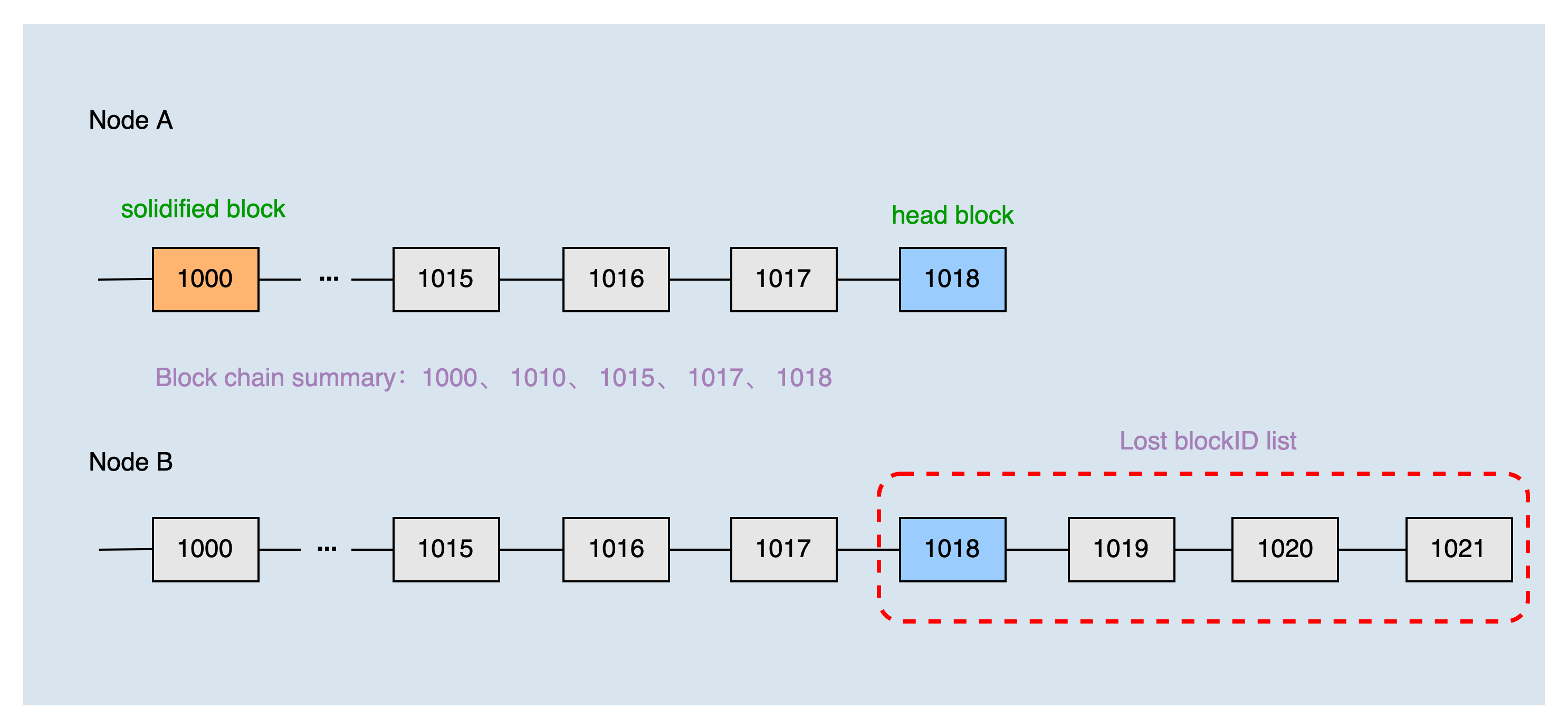
The height of the local header block is 1018, and the height of the solidified block is 1000. The two nodes have just established a connection, so the height of the common block is 0. The local blockchain summary of node A obtained by the dichotomy is 1000, 1010, 1015, 1017, and 1018.
After node B receives the blockchain summary of node A, combined with the local chain, it can produce the list of blocks that node A lacks: 1018, 1019, 1020, and 1021. Then, node A requests to synchronize blocks 1019, 1020, and 1021 according to the list of missing blocks.
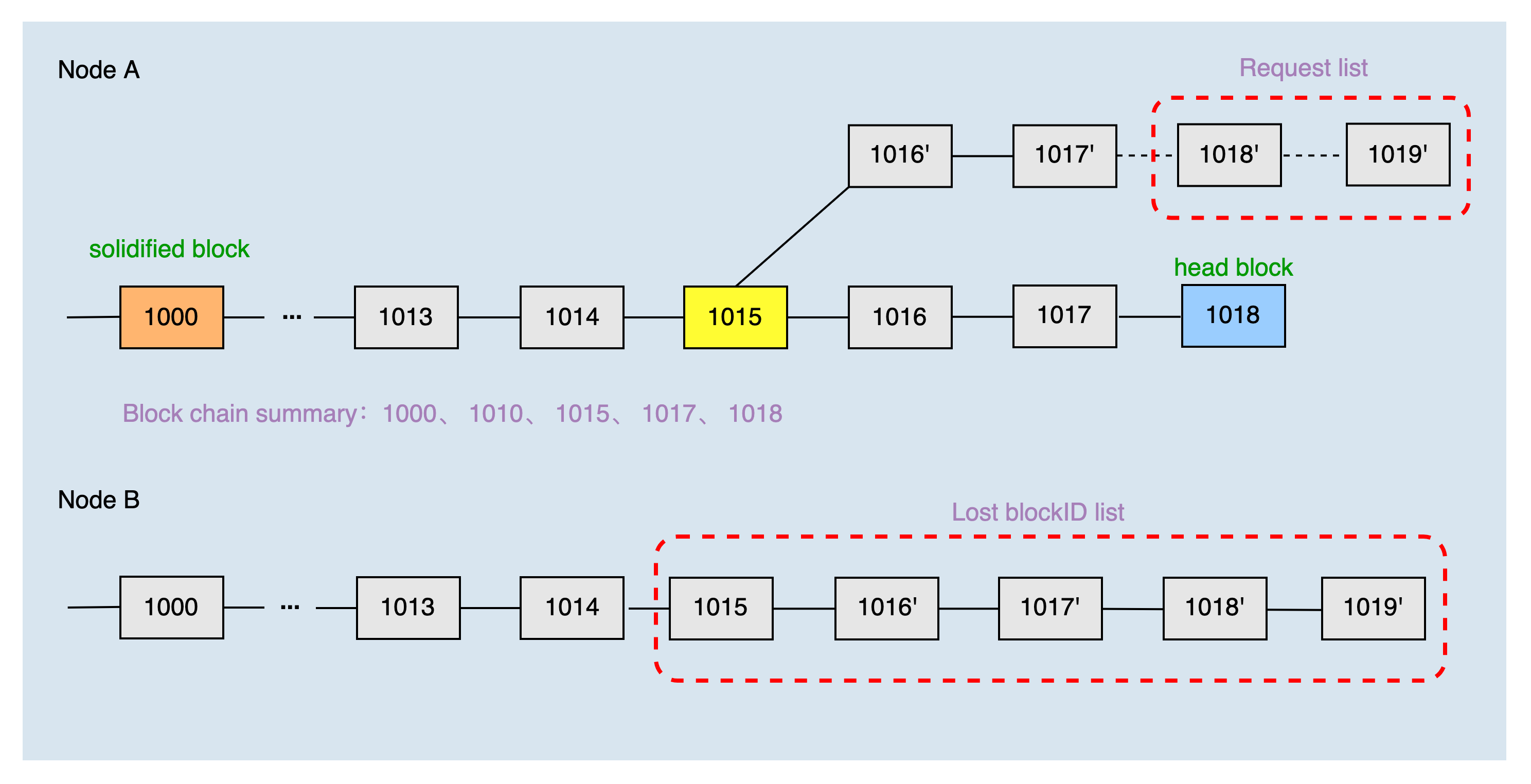
Chain-Switching Scene¶
The head block height of the local main chain is 1018, and the height of the solidified block is 1000. The two nodes have just established a connection, so the height of the common block is 0. The local blockchain summary of node A obtained by the dichotomy is 1000, 1010, 1015, 1017, and 1018.
After node B receives the chain summary of node A, it finds that the local main chain is not the same as the main chain of node A, compares the chain summary of node A and finds that the common block height is 1015, then it computes the list of blocks that node A lacks are 1015, 1016', 1017', 1018', and 1019'. Then, node A requests to synchronize blocks 1018' and 1019' according to the list of missing blocks.
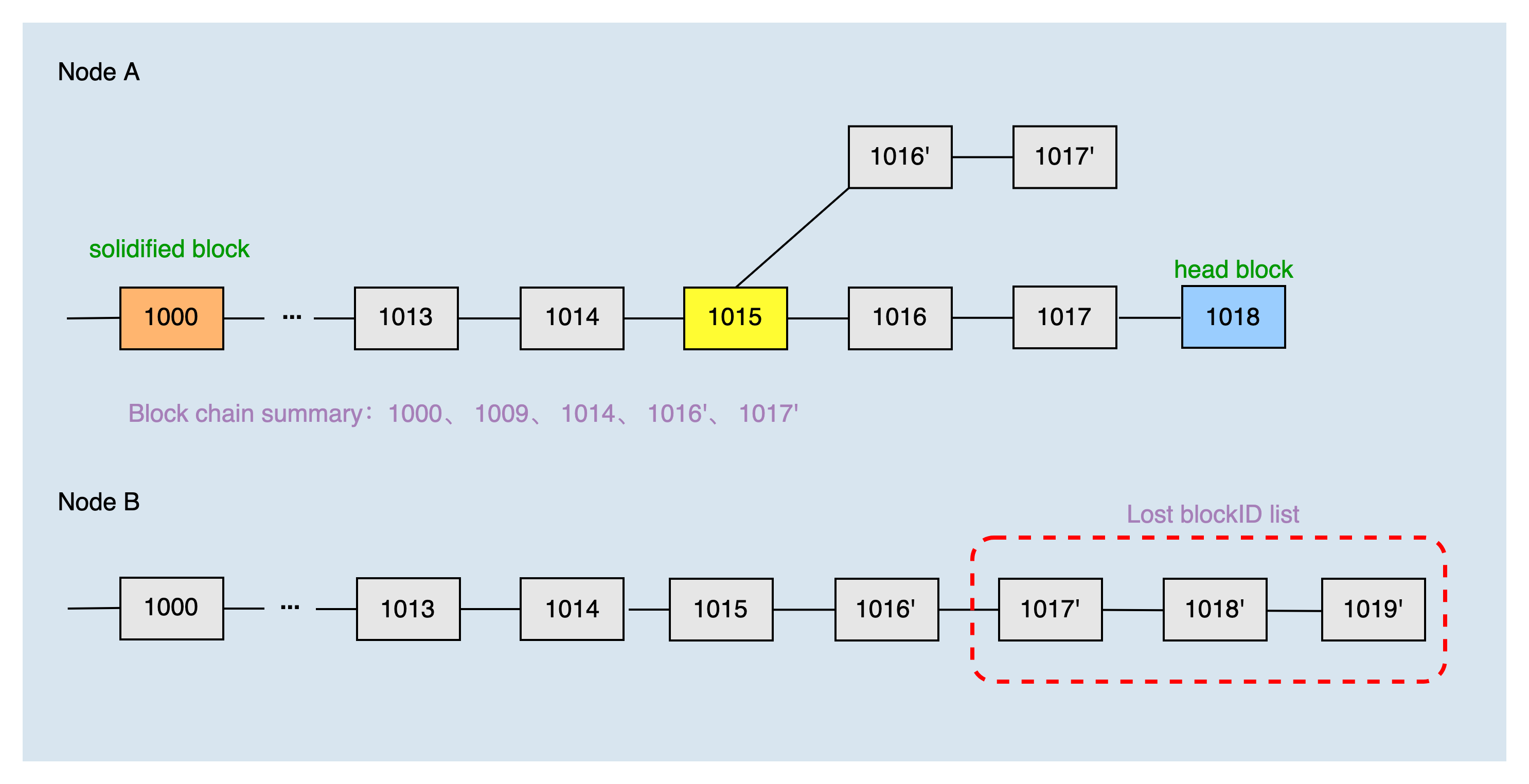
In another switching chain scenario, the height of the local main chain header block is 1018, the height of the solidified block is 1000, and the common block is 1017', which is located on the fork chain. The local blockchain summary of node A obtained by the dichotomy is 1000, 1009, 1014, 1016', and 1017'.
After node B receives the chain summary of node A, combined with the local chain, it can produce the list of blocks that node A lacks 1017', 1018', and 1019'. Then, node A requests to synchronize blocks 1018', and 1019' according to the list of missing blocks.
Block and Transaction Broadcast¶
When the super representative node produces a new block, or the fullnode receives a new transaction initiated by the user, the transaction & block broadcasting process will be initiated. When a node receives a new block or new transaction, it will forward the corresponding block or transaction, and the forwarding process is the same as that of broadcasting. The message interaction is shown in the following figure:
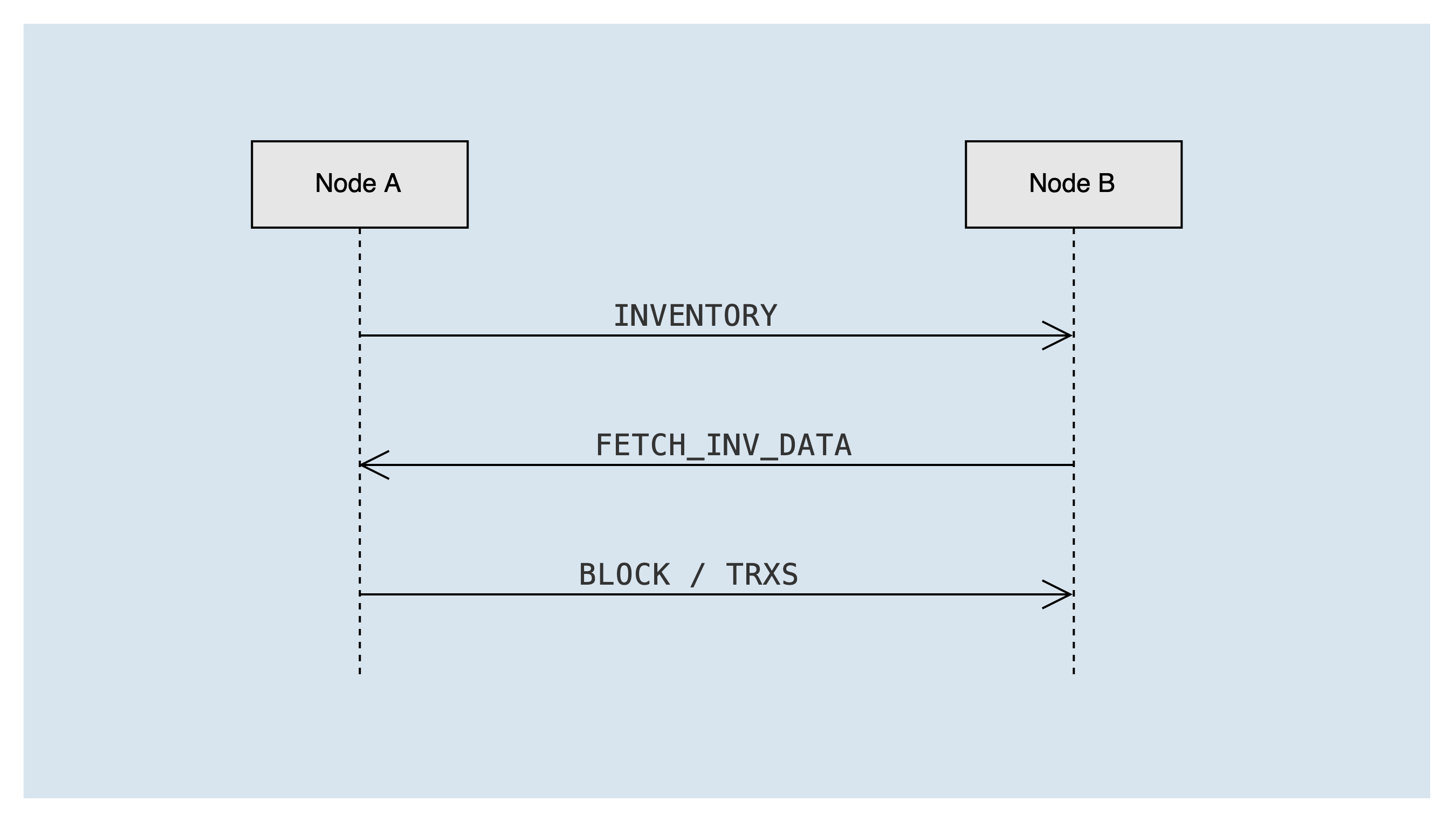
The types of messages involved include:
INVENTORY- broadcast list: list of block or transaction idsFETCH_INV_DATA- the list data that the node needs to get: block or transaction id listBLOCK- block dataTRXS- transaction data
Node A sends the transaction or block to be broadcast to Node B via the INVENTORY list message. After node B receives the INVENTORY list message, it needs to check the status of the peer node, and if it can receive the message, it puts the blocks/transactions in the list into the "to be fetched queue" invToFetch. If it is a block list, it will also trigger the "get block & transaction task" immediately to send a FETCH_INV_DATA message to node A to get the block & transaction.
After node A receives the FETCH_INV_DATA message, it will check whether an "INVENTORY" message has been sent to the peer. If it has been sent, it will send a transaction or block message to node B according to the list data. After node B receives the transaction or block message, it processes the message and triggers the forwarding process.
Summary¶
This article introduces the P2P network, the lowest level module of TRON. Node discovery and node connection have been extracted into the external libp2p dependency and are only briefly located here; block synchronization and the process of block and transaction broadcasting, which remain in java-tron's core/net, are introduced in detail. I hope that reading this article can help developers to further understand and develop java-tron network-related modules.